DocTr_3_GeoTr
본 포스트는 DocTr의 GeoTr 과정을 상세히 저술합니다.
* 본 포스트에 사용되는 모든 자료는 직접 코드를 살펴보고 시각화하여 만든 것이니, 사용하실 분은 댓글 남겨주시길 바라겠습니다.
이전 과정을 보시면 이해가 더 원활할 것 같으니,
🔻 1편
2023.03.15 - [비전딥러닝/논문review] - DocTr_1
DocTr_1
본 포스팅에서는 DocTr의 전체적인 과정과 논문 리뷰를 합니다. 구체적인 동작 구조와 코드 리뷰는 2편을 참고하시길 바랍니다! 논문 url https://arxiv.org/pdf/2110.12942.pdf DocTr 이전 선행연구들 DocTr Proce
chaem.tistory.com
🔻 2편
2023.03.16 - [비전딥러닝/논문review] - DocTr_2_UNETP
DocTr_2_UNETP
본 포스트는 DocTr의 세부적인 동작 구성과 코드 리뷰를 담은 포스트입니다. * 본 포스트에 사용된 모든 자료는 코드를 살펴보고 직접 만든 것이니, 혹시 사용하실 분이 계신다면, 댓글 남겨주시
chaem.tistory.com
을 보고 오시는 걸 추천드립니다!

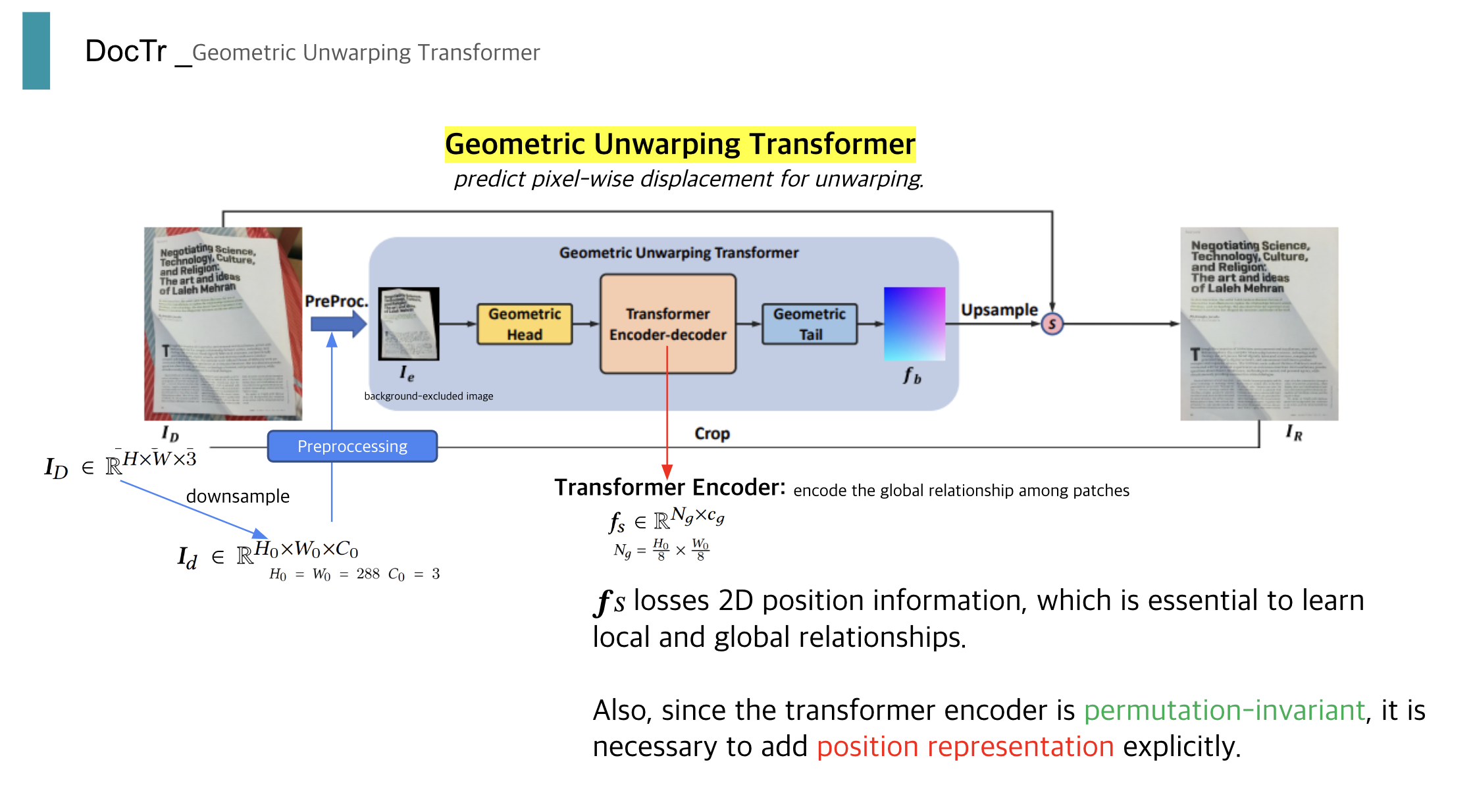
저번 편에서 간단한 (?) segmentation network의 과정을 살펴보았으니, 이제 본격적으로 배경과 분리된 종이가 dewarping 되도록 flow map을 output으로 하는 GeoTr의 과정을 살펴볼 예정입니다.
GeoTr
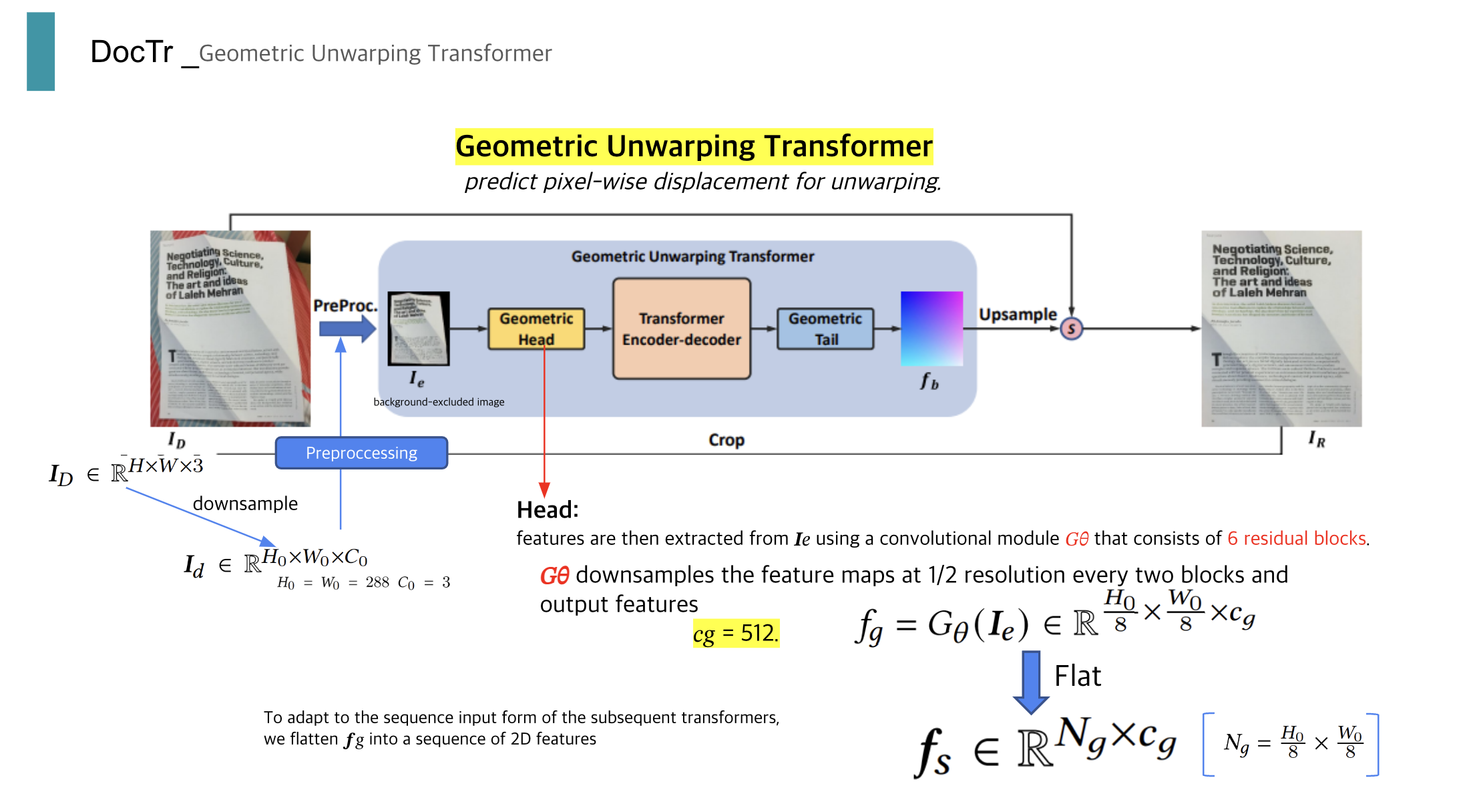
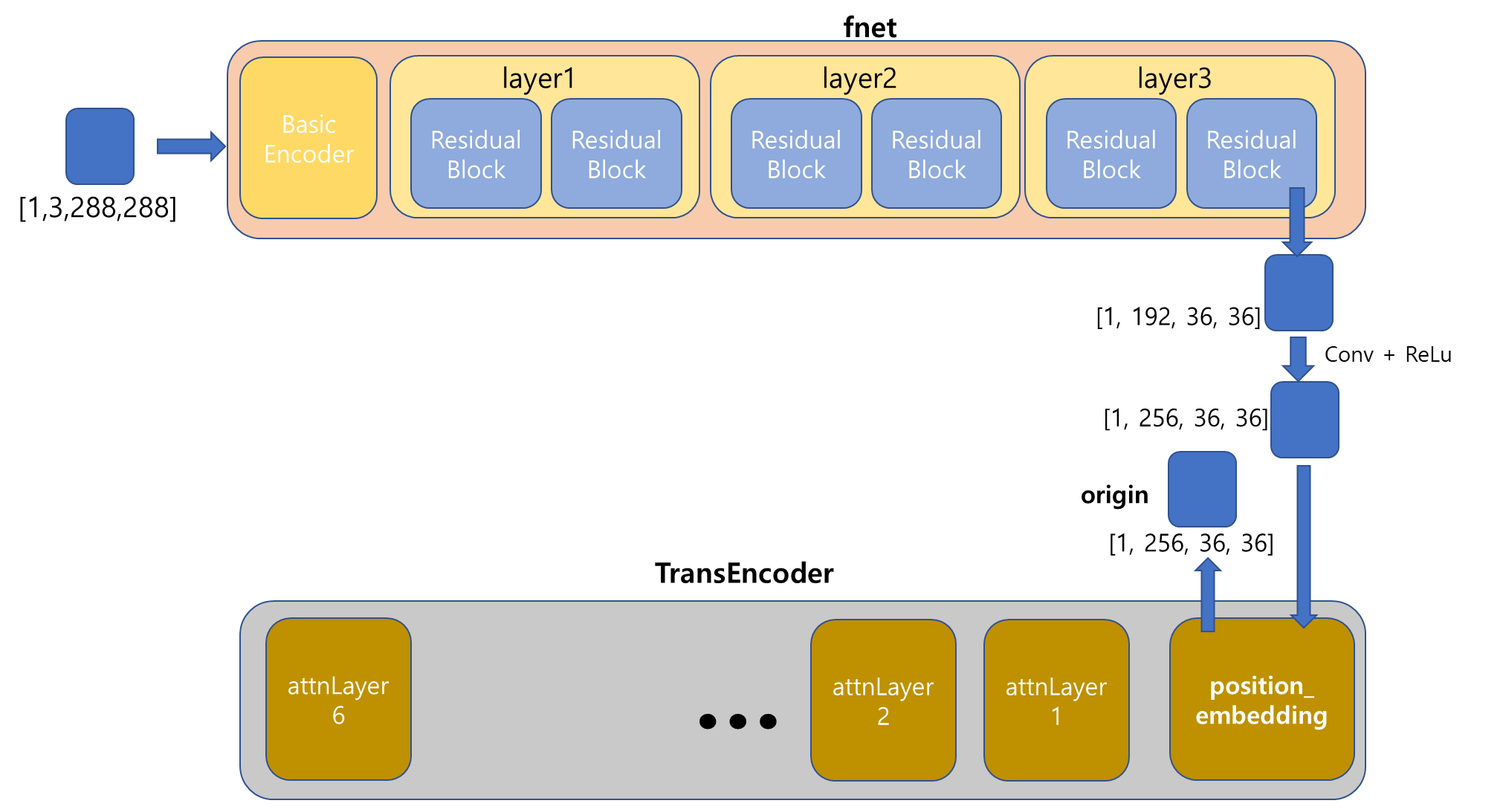
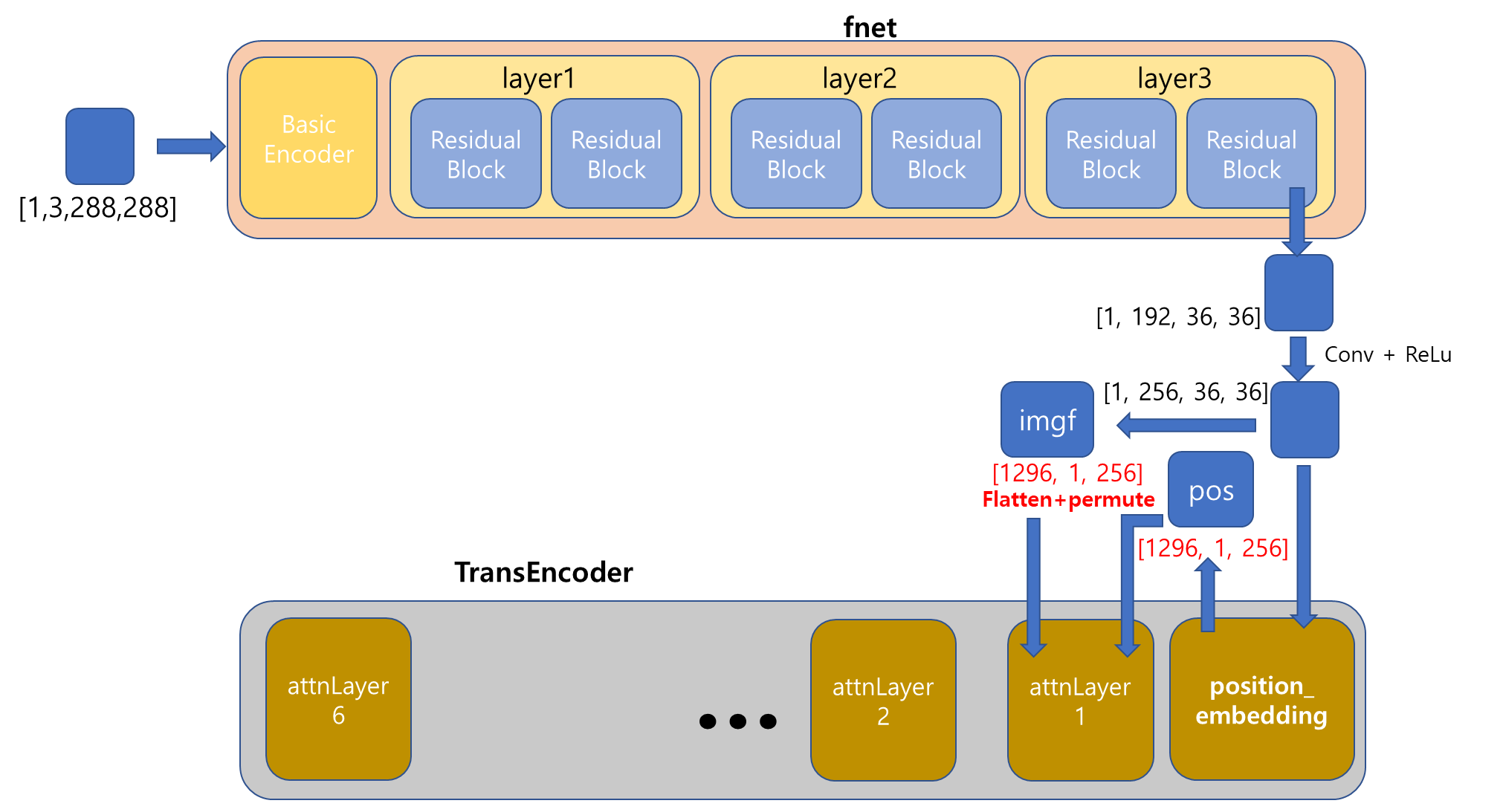
Gemetric Head 라는 과정에서 segmentation 된 [1,3,288,288]의 tensor를 처리한다고 한다.
이는 6개의 residual block들로 이루어졌다고 하는데, 코드를 통해 정확히 어떻게 진행되는지 알 수 있었다.
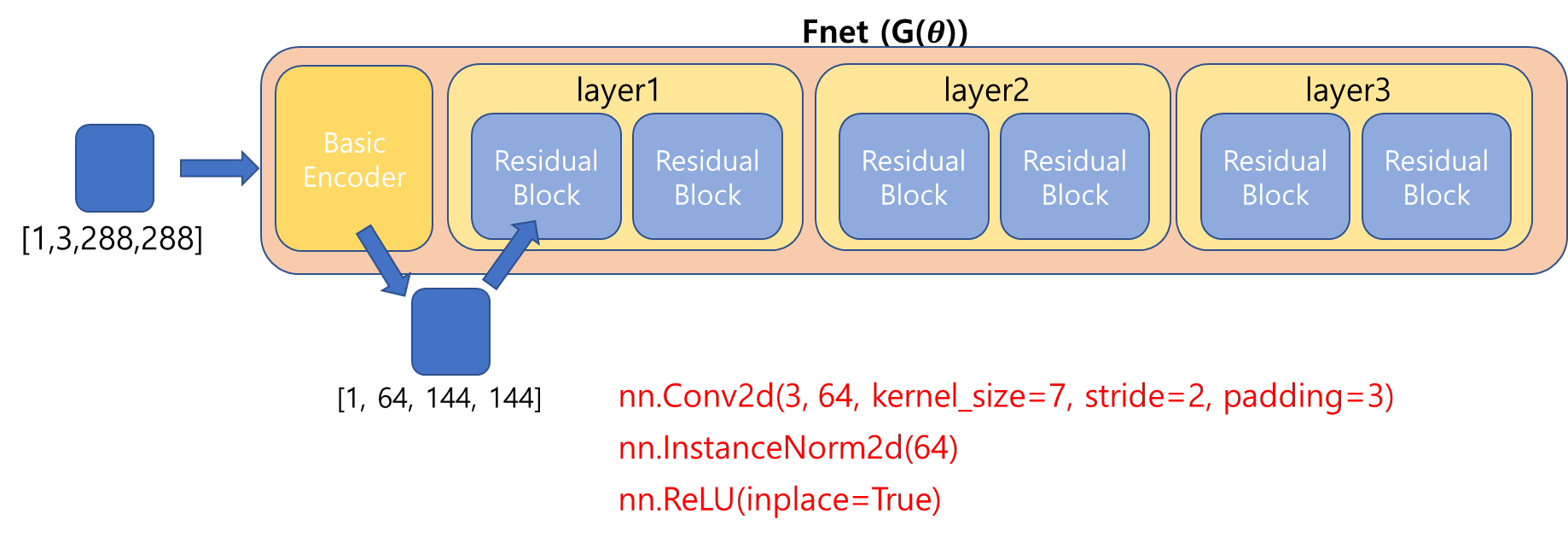
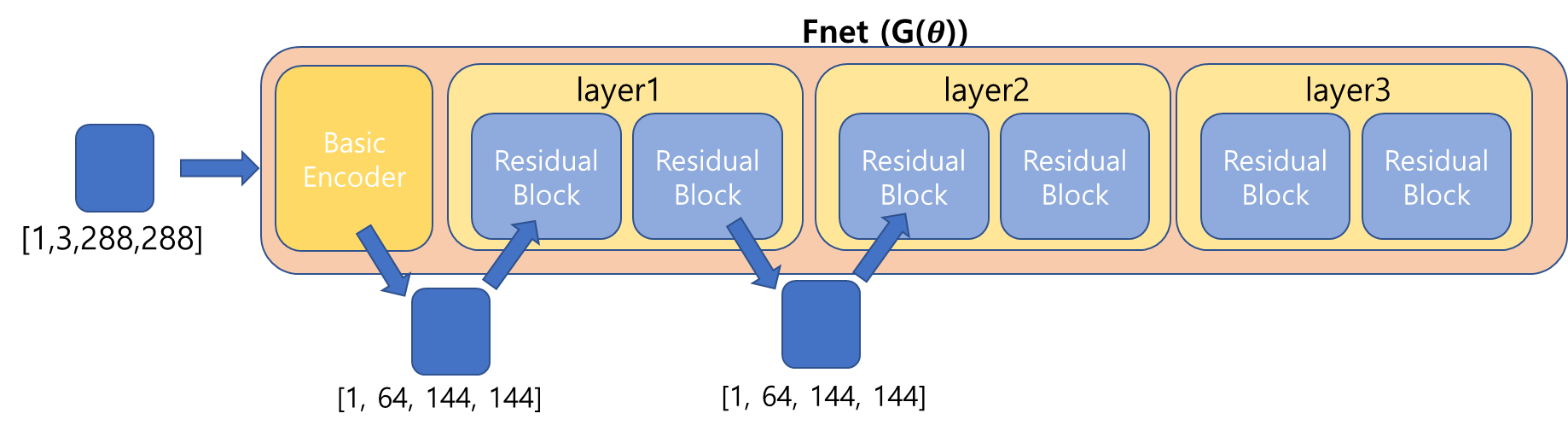


Head 과정이 끝났다. [1,256,36,36]의 Tensor가 이제 Transformer의 Encoder로 들어갈 것이다.
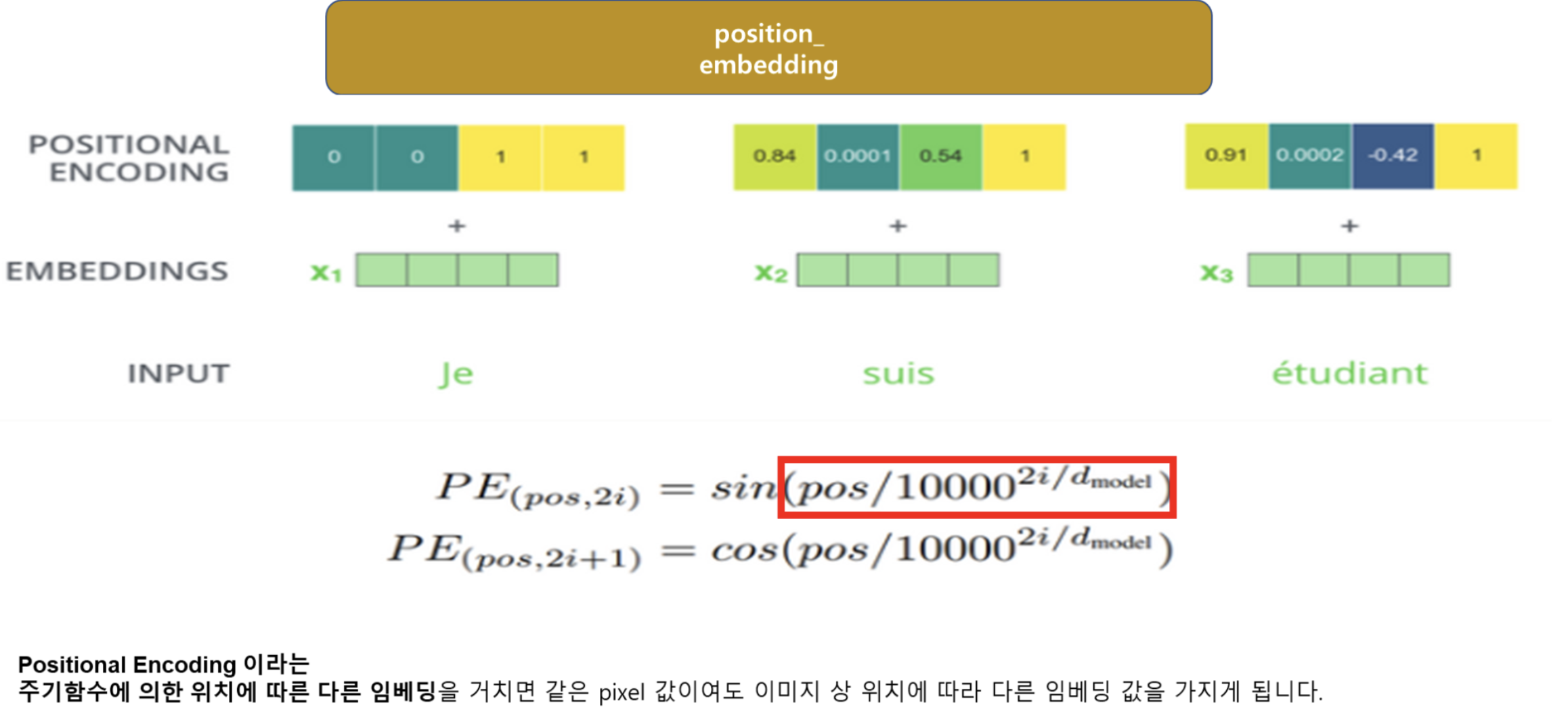
Transformer _ encoder




POS 구하는 과정

👇 빨간 박스의 과정은 이렇게 진행됩니다.,


👇 빨간 박스의 과정은 이렇게 진행됩니다.,
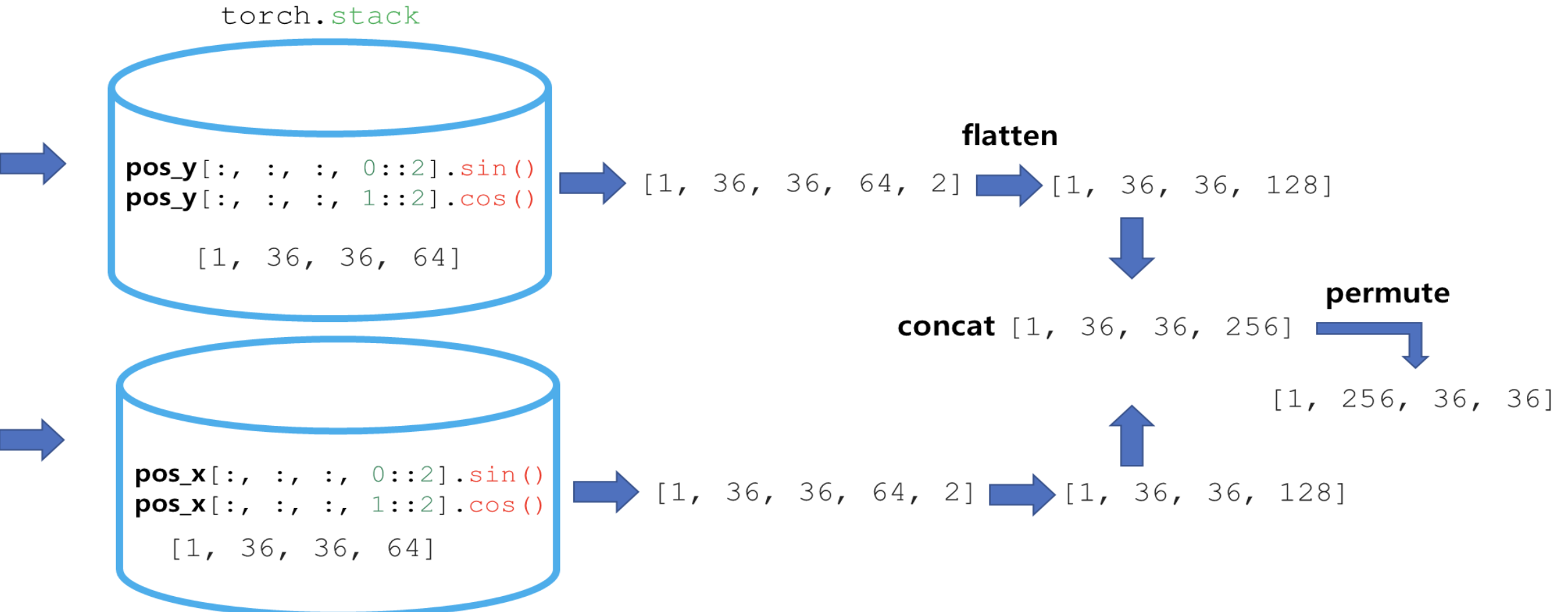
이렇게 길고 긴 Position_Embedding 과정이 끝나고, [1,256,36,36] Tensor가 Output으로 출력되었습니다.
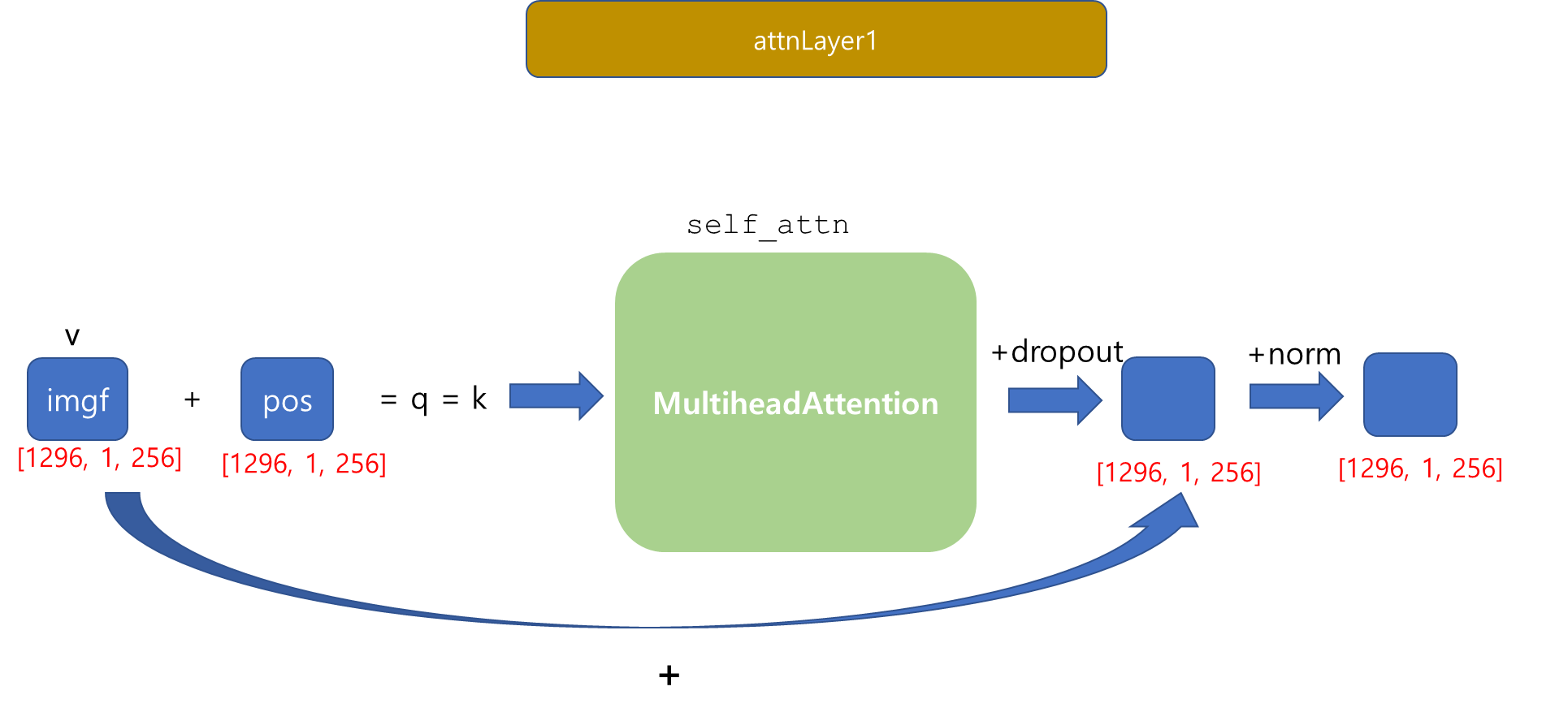
🤔 여기서 잠깐! MultiheadAttention이란?

+ Attention하니까 뉴진스 갓기들이 생각나네요.. 제 아가들입니다..
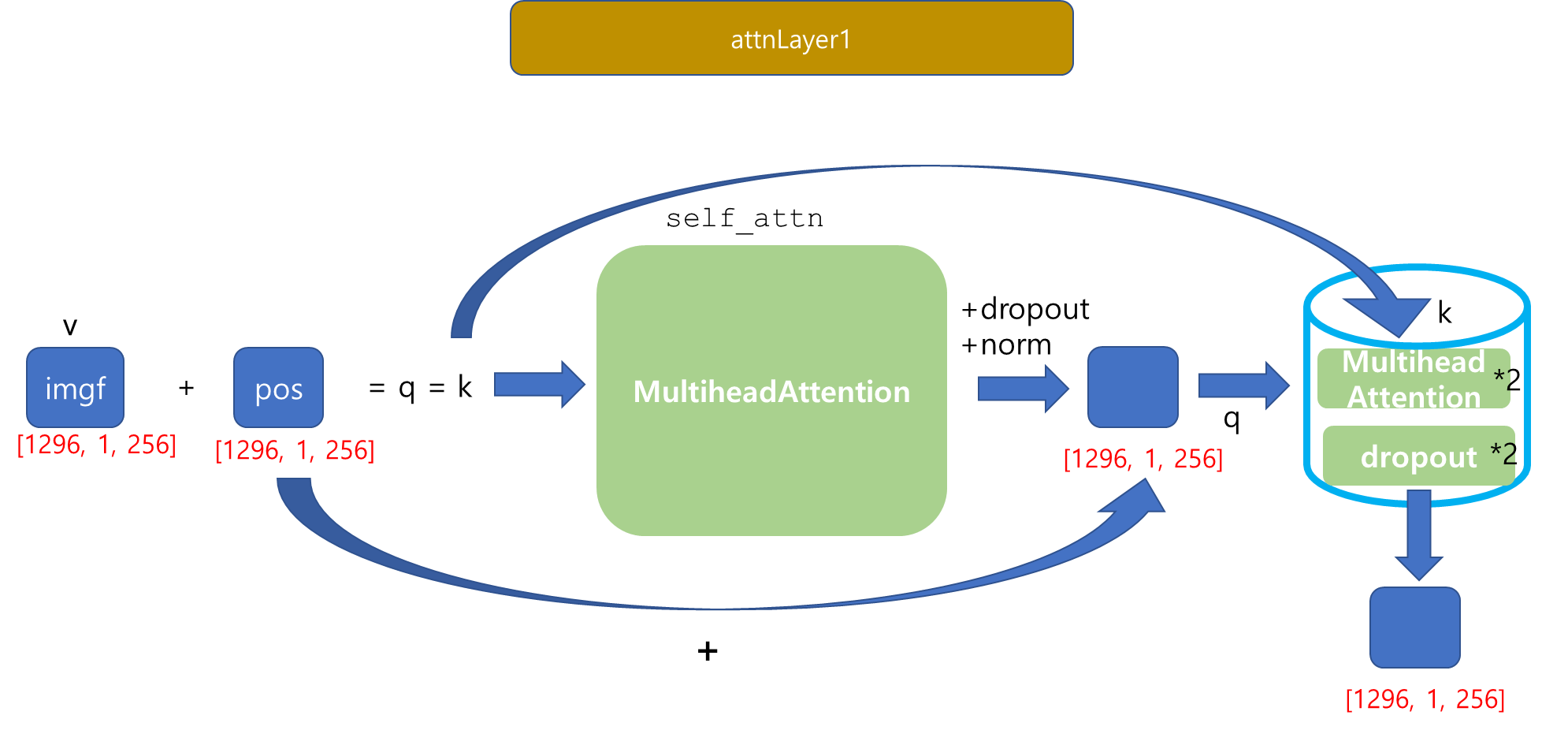
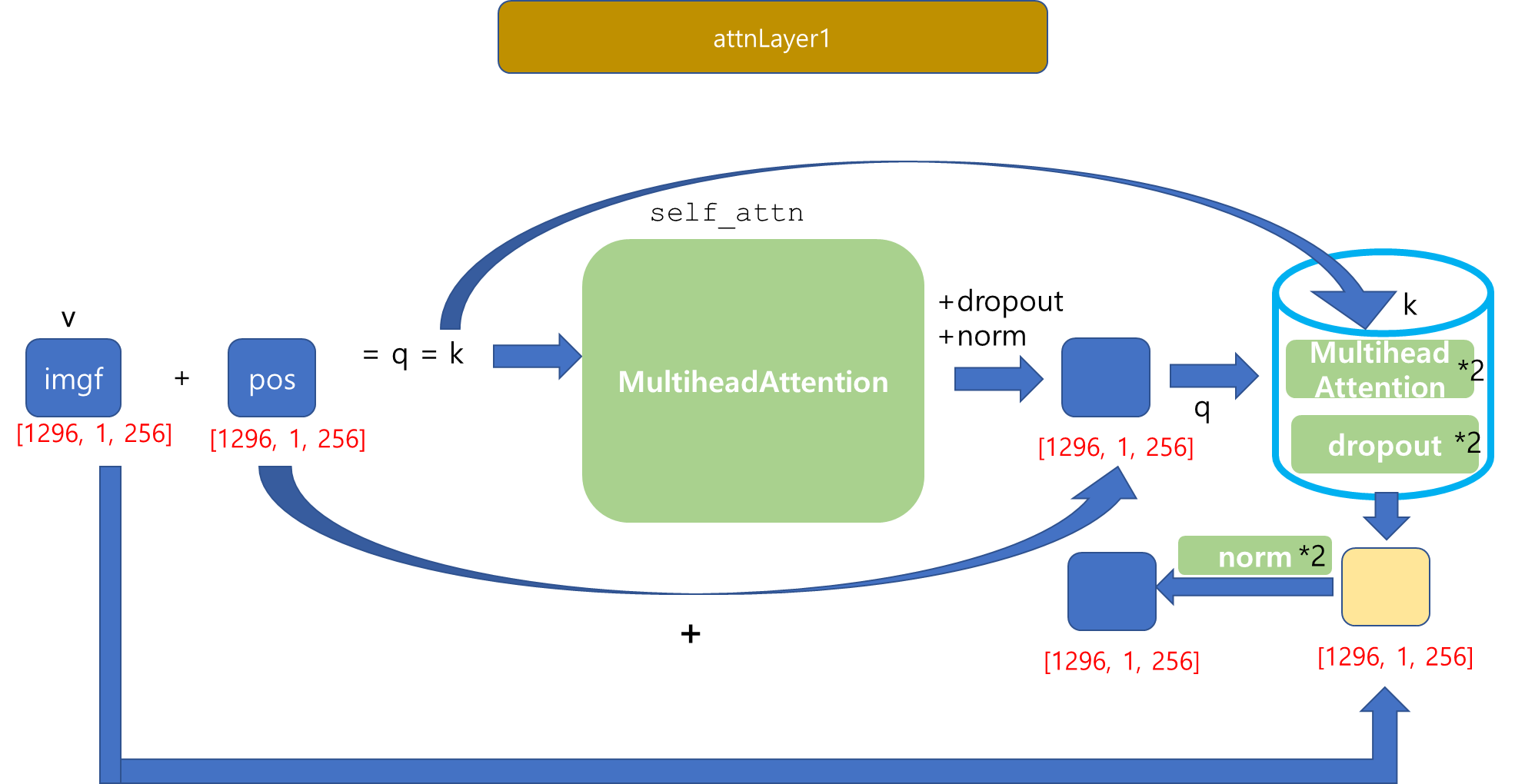
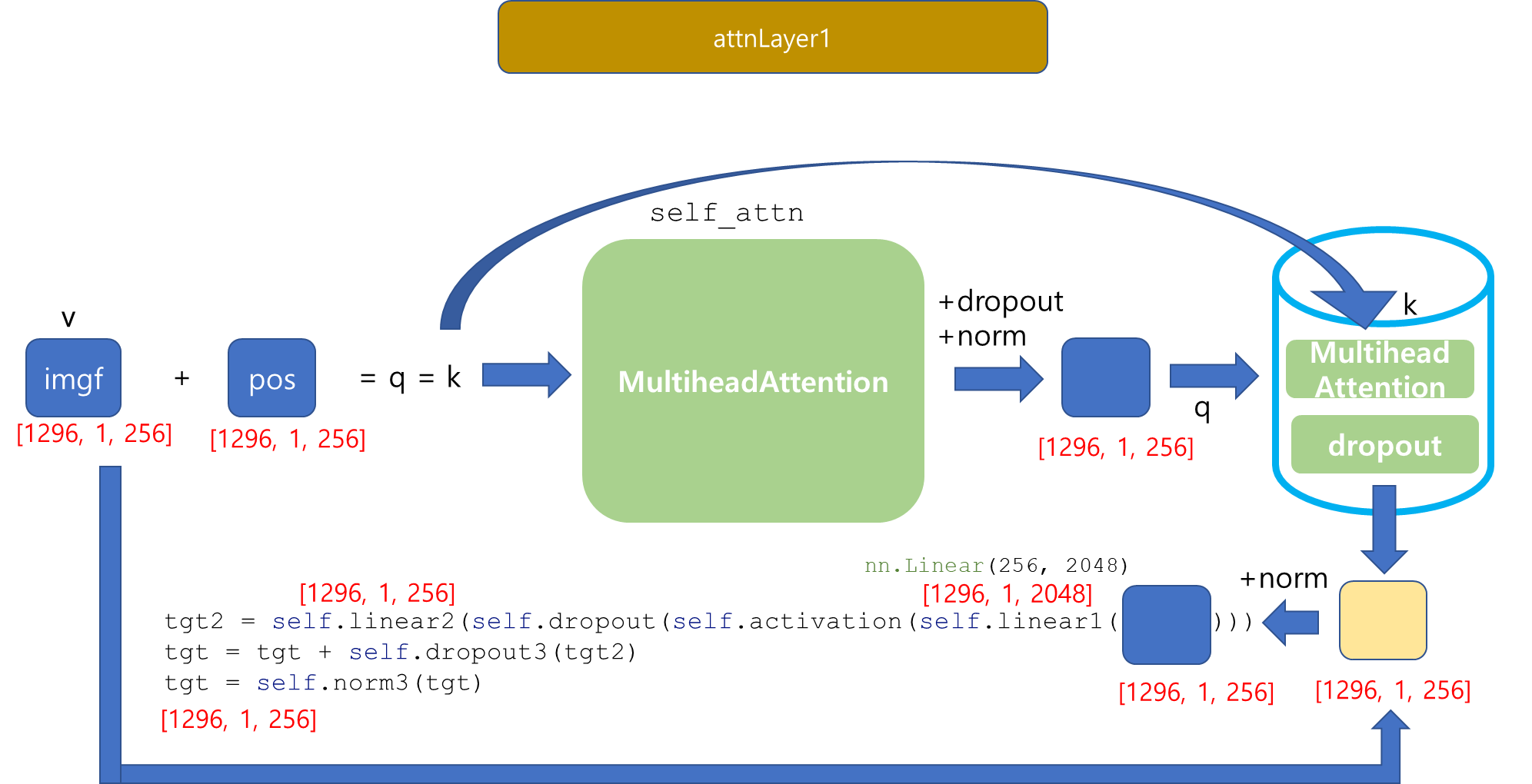



Transformer의 Encoder의 최종 output을 도출했습니다...!
Decoder는 다음 편에 계속 ✨