사실, 딥러닝 중에서도 비전 딥러닝을 먼저 접해보고, 머신러닝에 대해서는 딱히 아는 바가 없는 감자라서, 이번 연수 기회에 열심히 배우고자 했다.
참고로 나는 19학번으로 인공지능 전공 자체가 입학할 때 없었으며, 부전공이나 복수전공을 하기에는 너무 늦었지만, 컴퓨터 비젼 (영상처리, 비젼 과목 등) 전공을 학부에서 접해보면서 딥러닝을 알아야 겠다고 느껴, 비전 딥러닝 관련 회사에서 1년 정도 인턴을 하면서 논문 리뷰 및 CNN 모델 설계, 모델 학습, 데이터 처리 등을 겪어본 바 있다.
AI 관련해서 내가 지금 아는 것 (제대로 아는 건지도 잘 모르긴 함)
필요한 것 (아마도?)
- Object Detection - Segmentation - Transformer - 데이터 증강하는 법 (합성 등) - Python, Tensorflow, Pytorch - 시각화 (TensorBoard) - 비전 관련 학부 수준의 전공 지식
- 머신러닝 이론 지식 및 sklearn - 시계열 데이터 분석을 비롯한 데이터 분석 (Pandas,R 등) - 시각화 (R,Seaborn 등) - 딥러닝
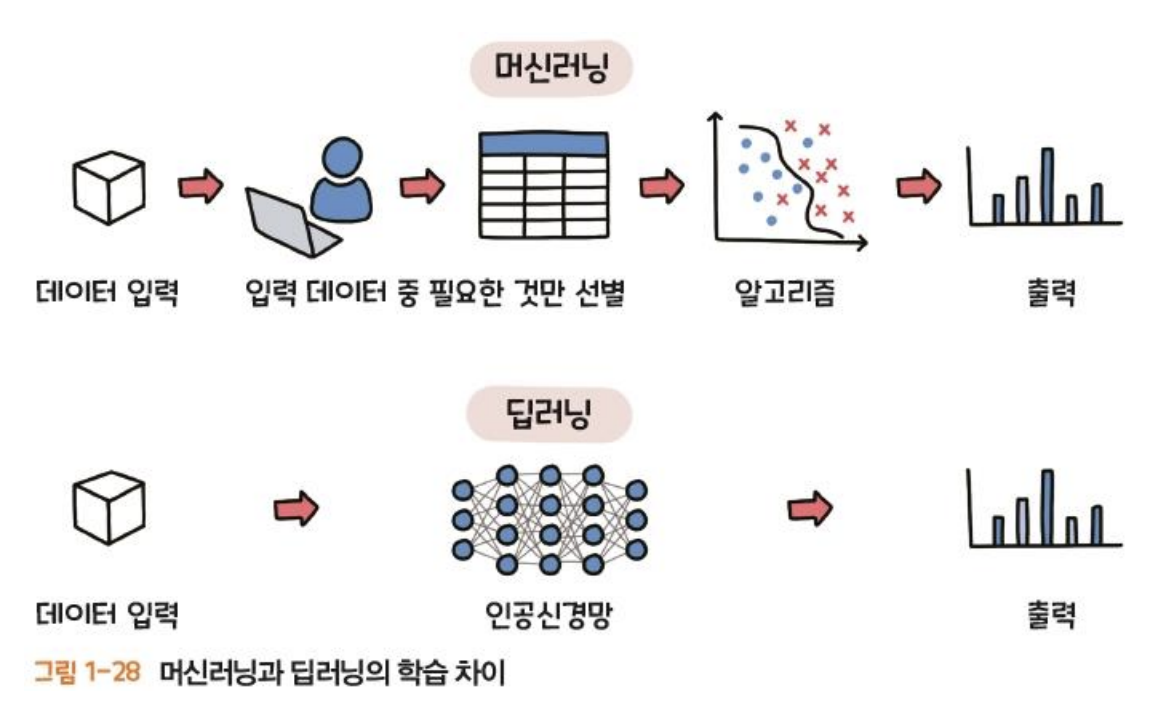
출처 : https://wooono.tistory.com/206
위 그림에서 본 것과 같이, 머신러닝을 하기 위해선 데이터 선별, 분석 작업이 굉장히 중요하다.
이 과정에 따라 모델의 성능이 확확 바뀌기때문이다.
따라서, 머신러닝의 첫 포스트인 해당 포스트에서는 데이터 처리와 학습 과정을 전체적으로 살펴볼 것이다.
이 링크에서 csv 파일 하나를 다운받고 주피터 파일을 열어 대충 데이터 사용해보면 된다. 여기는 아마 train.csv를 불러올텐데, 그냥 단순히 colab에 다운 받은 파일 넣고 해당 파일 이름으로 바꿔주거나, 해당 파일명을 train.csv로 바꾸면 된다.
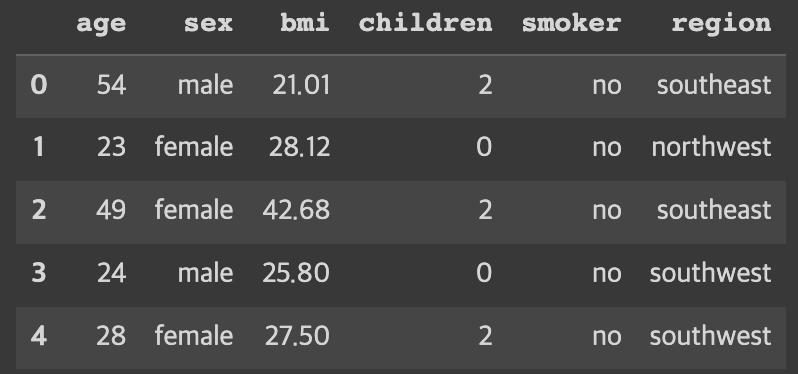
어느 데이터든 가장 중요한 것이자 가장 처음에 해야할 것은 '컬럼 분석' 인 것 같다.
해당 데이터의 컬럼명과 의미를 먼저 파악하고, '타겟 설정'을 해야한다.
우리는 '의료 보험비 예측'을 하는 모델을 만들 것이므로, y 값, 즉 정답을 charges, 의료 보험비 칼럼으로 한다.
=> 학습 데이터는 charges 칼럼을 제외한 모든 칼럼, 라벨은 charges 칼럼이다.
Pandas,Seaborn과 같은 라이브러리를 먼저 다룰 줄 알아야 시각화와 데이터 분석을 얕게나마 해볼 수 있다
👩🏼💻 Pandas란?
Pandas 유용한 것들 - pd.CreateDataFrame() - pd.read_csv(경로) - dataframe.describe() : mean, 표준편차 등을 정리 - dataframe.corr() : 데이터 간 상관관계 출력, 보통 seaborn의 heatmap 안에 넣어서 시각화한다. ....
🧑🏫 Seaborn 이란?
❗️Label Encoding
sex 와 smoker, region은 문자열이 들어가 있으므로, 이를 숫자로 변환해, 모델이 학습할 수 있도록 만들어줘야 한다!
# apply 함수 이용
train['sex'] = train['sex'].apply(lambda x: 1 if x == 'male' else 0)
test['sex'] = test['sex'].apply(lambda x: 1 if x == 'male' else 0)
#map 함수 이용
dic = {
"male":1,
"female":0,
}
train['sex'] = train['sex'].map(dic)
test['sex'] = test['sex'].map(dic)
위와 같이 apply 함수를 통해 해줘도 되고, map 함수를 통해 해줘도 된다.
❗️ 모델 선정
머신러닝 모델을 직접 구현할 필요가 없다!
왜냐면 sklearn이 다 제공해주기 때문이다... 여기서 나오는 이론적 배경은 후에 자세히 다룰 예정이다.
일단은 앙상블 모델을 사용해 보니, 가장 성능이 좋아서 이걸 사용할 것이다!
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor