[Object Detection] Yolo + traditional Solution
https://arxiv.org/abs/1506.02640
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
[Reference]
https://www.youtube.com/watch?v=O78V3kwBRBk&t=254s
주로 이 분의 발표를 바탕으로 yolo를 이해할 수 있었으며, 이 발표를 바탕으로 제가 이해한 내용을 정리한 포스트입니다!

object detection task란, 일종의 object classification과 object localization을 합친 task로, 이미지 내의 모든 object에 대해 class를 매기고, 그 위치를 파악해 bounding box를 도출하는 task입니다.
따라서, 이 task를 수행하는 모델의 output은 각 object에 대한 class 확률과 bounding box를 위한 center point의 x,y좌표, 그리고 그 너비와 높이입니다.
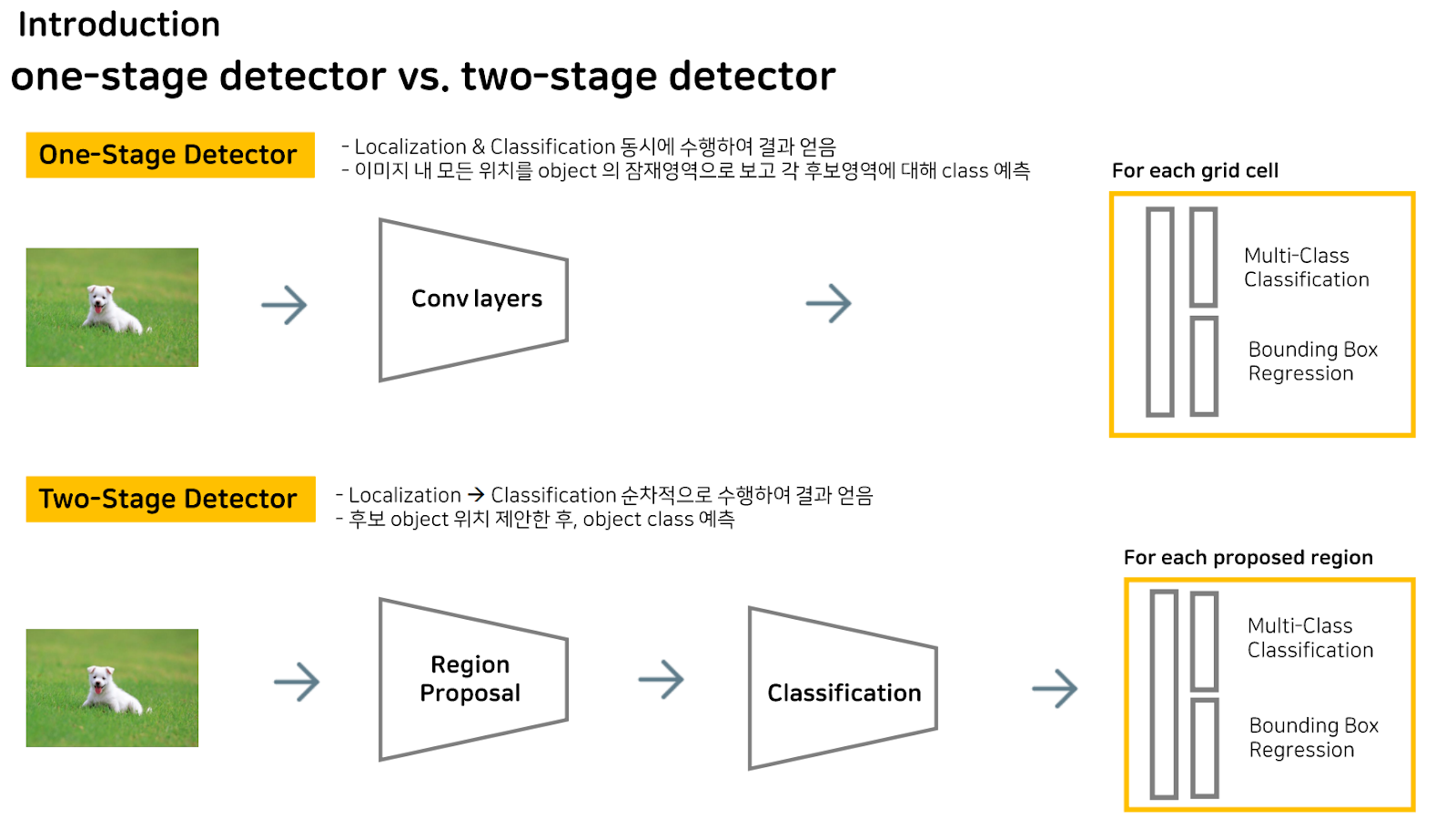
Object detection task를 수행하는 모델의 방식은 크게 두 가지로 나눌 수 있습니다.
One-Stage 와 Two-Stage인데요, 간단히 말하자면, One-Stage는 말 그대로 bounding box 예측과 Classification을 한 번에 같이 수행하는 것이고, Two-Stage는 object가 있을 공간을 먼저 예측하고, 그 다음 classification을 수행하는 방식입니다.

더 구체적으론, One-Stage Detector는 이미지를 입력받아 ocnv연산과 Fc layer를 거치고 reshape를 통해 각 그리드 셀마다 classification 결과와 bounding box의 좌표값을 얻어내게 됩니다.
Two-Stage Detector는 object의 영역부터 먼저 찾기에 region proposal을 수행해 object가 가장 있음직한 영역을 뽑아내고, 이를 원본 이미지를 classification한 것에 투영한 다음 fc layer를 거침으로써 One-Stage Detector와 마찬가지로, 각 그리드 셀마다 classification 결과와 bounding box의 좌표값을 얻어내게 됩니다.
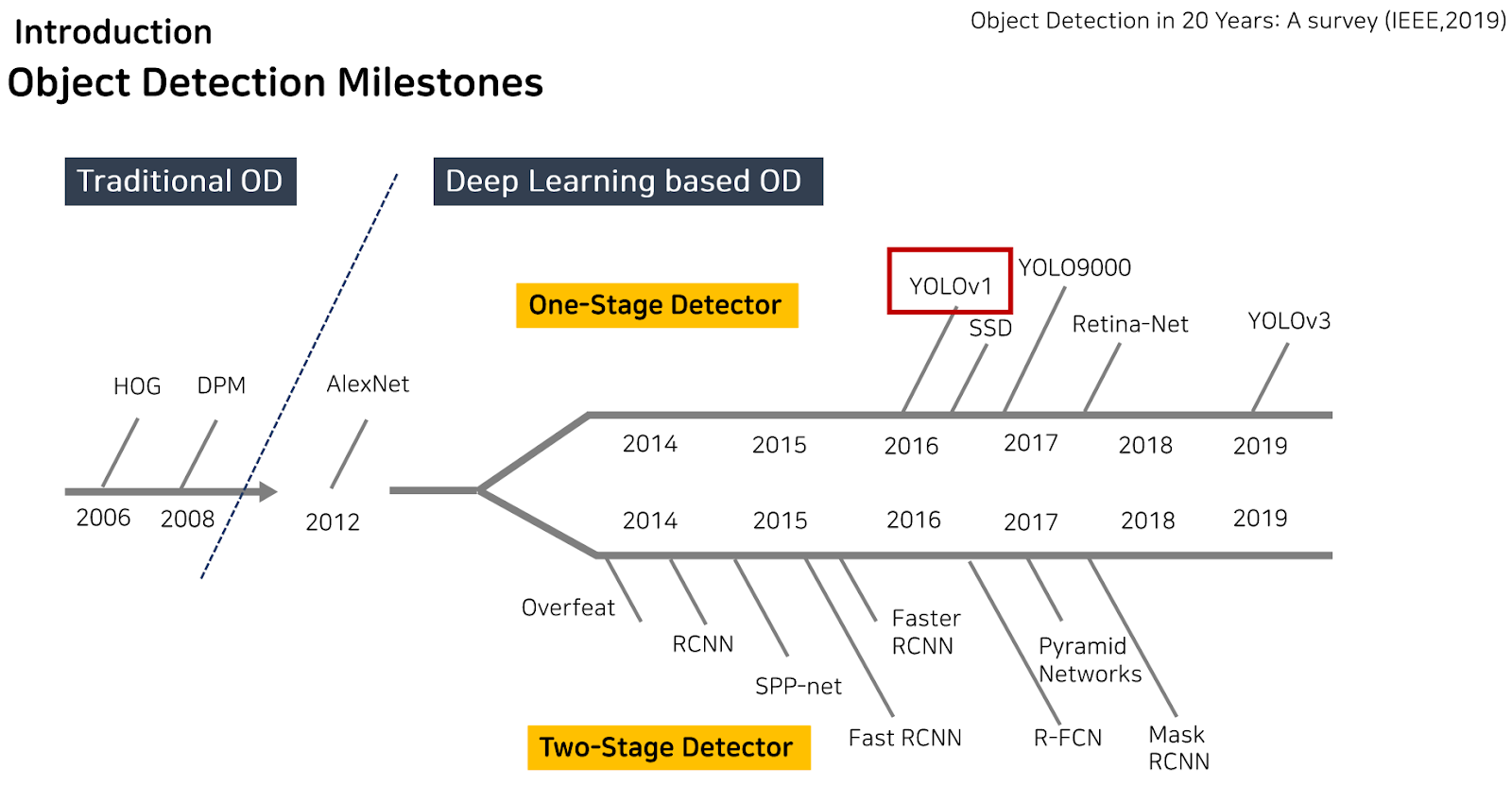
Object detection task를 수행하는 모델의 변천사입니다. 두 방식에 해당되는 대표적인 모델들이 정리되어 있는데, One-Stage Detector 방식은 Yolo, SSD가 대표적이고, Two-Stage Detector 방식에는 FastRCNN 등이 있습니다.
딥러닝을 이용한 Object detection task를 수행하는 모델을 소개하기 전에, 딥러닝을 이용하지 않고는 어떻게 Object detection을 수행하는지에 대해 간략히 설명드리겠습니다.
Traditional Object detection

HoG에서는 영상의 feature를 기본적으로 방향에 따른 gradient 값의 histogram으로 표현합니다.
먼저, 입력 영상으로부터 각 pixel의 Gradient 크기와 방향을 계산해야합니다.
각 pixel을 순회하면서 인접한 x방향, y방향으로의 절대값을 구한다음, 각각 제곱하고 루트를 씌워주면 Gradient Magnitude 값에 근사한 값이 나오게 됩니다. Gradient Direction은 x방향의 gradient에 y방향의 그래디언트를 나눈 다음 역 탄젠트를 씌우면 값을 얻을 수 있습니다.
이 gradient magnitude 값과 direction 값으로 histogram을 만들고, normalization을 해줘서 배수의의미가 없어지도록 만듭니다.
9방향의 gradient histogram 4개가 한 block마다 있으므로 각 block은 36개의 feature를 갖게 됩니다.
이렇게 구해진 feature vector와 레이블로 이루어진 쌍은 선형 SVM 분류기를 통해 학습되어 object detection을 수행하게 됩니다.
SVM은 이진 분류 탐색기로, 데이터들을 구분짓는 hyper plane, W^tx+b=0에서 margin을 최대화 시키는 W를 구하는 머신러닝 알고리즘인 것으로 알고 있습니다.

또한, K-means 알고리즘을 활용해 Object detection을 수행할 수 있습니다.
K-means 알고리즘은 군집화 알고리즘의 대표적인 알고리즘으로, AI에서는 주로 비지도 학습에 사용됩니다. 이 알고리즘은 다들 아시다시피, k개의 centerpoints를 주변 점들의 거리가 최소화 되는 위치로 찾는 것입니다.
이렇게 center point를 찾으면 그 점이 바로 object의 center point가 되는 것이며, 적절한 width,height를 줘서 bounding box를 도출할 수 있습니다.
하지만, Object Detection에서의 classification은 수행하기 어렵다는 점과, k의 초기화가 매우 중요하다는 단점이 있습니다.
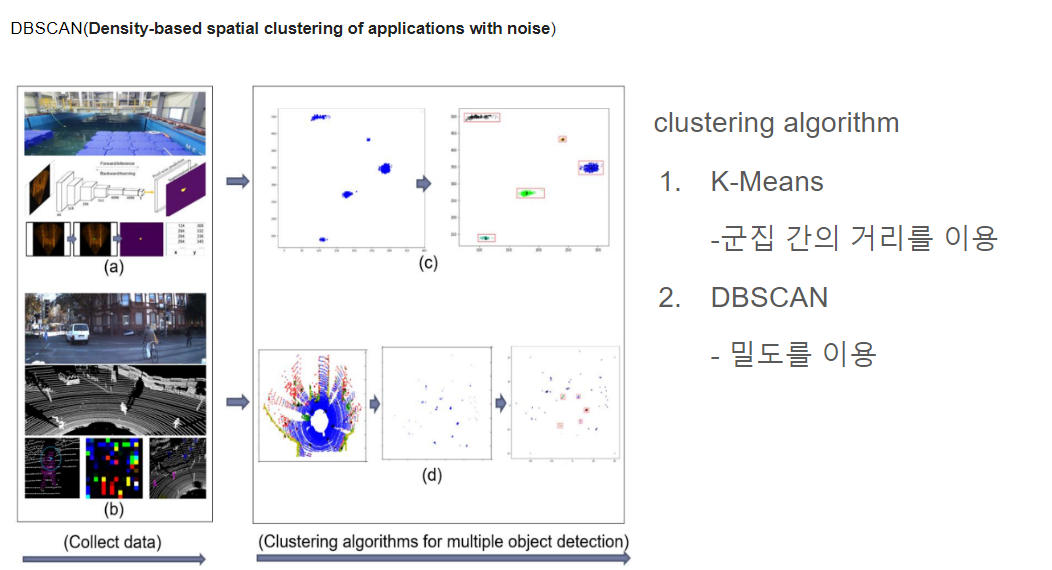
군집 내의 거리를 이용해 center point를 찾는 K-means보다 밀도를 이용해서 찾는 DBSCAN이라는 알고리즘이 더 성능이 좋다는 결과가 있어, 가지고 와봤습니다.

[Reference]
클러스터링 #3 - DBSCAN (밀도 기반 클러스터링)
DBSCAN (밀도 기반 클러스터링) 조대협(http://bcho.tistory.com)기본 개념이번에는 클러스터링 알고리즘중 밀도 방식의 클러스터링을 사용하는 DBSCAN(Density-based spatial clustering of applications with noise) 에 대
bcho.tistory.com
DBSCAN은 점 p가 있다고 할때, 점 p에서 부터 거리 e (epsilon)내에 점이 m(minPts) 개 있으면 하나의 군집으로 인식합니다. 즉 거리 e 내에 점 m개를 가지고 있는 점 p를 core point (중심점) 이라고 합니다.
예시를 보시면, P로부터 epsilon 반경 내에 있는 점의 개수가 p까지 총 5개이므로 조건을 만족해 cluster에 해당합니다. 그 다음, P2를 기준으로 봤을 때, 조건을 만족하지 못하므로, core point는 되지 못하지만 ,P를 core point로 하는 군집에는 포함되므로, boder point라고 합니다. 그 다음에는 p3를 봅니다.
P3를 중심으로 하는 반경내에 다른 core point P가 포함이 되어 있는데, 이 경우 core point P와 P3는 연결되어 있다고 하고 하나의 군집으로 묶이게 됩니다.
P4의 경우는 어느 군집에도 속하지 않는 outlier로, 이를 noise point라고 합니다.
DBSCAN 알고리즘을 사용하려면 기준점 부터의 거리 epsilon값과, 이 반경내에 있는 점의 수 minPts를 인자로 전달해야 합니다.
이렇게 밀도에 기반한 알고리즘은 DBSCAN은 K Means와 같이 클러스터의 수를 정하지 않아도 되며, 클러스터의 밀도에 따라서 클러스터를 서로 연결하기 때문에 기하학적인 모양을 갖는 군집도 잘 찾을 수 있다는 장점이 있어, K means에 비해 더 detection을 잘 한다는 연구 결과가 있습니다.
이제, 다시 yolo에 대해 말씀드리도록 하겠습니다.
yolo는 현재 version 7까지 나온 역사가 깊은 모델로, One-Stage 방식 중 대표적인 모델이라고 할 수 있습니다.
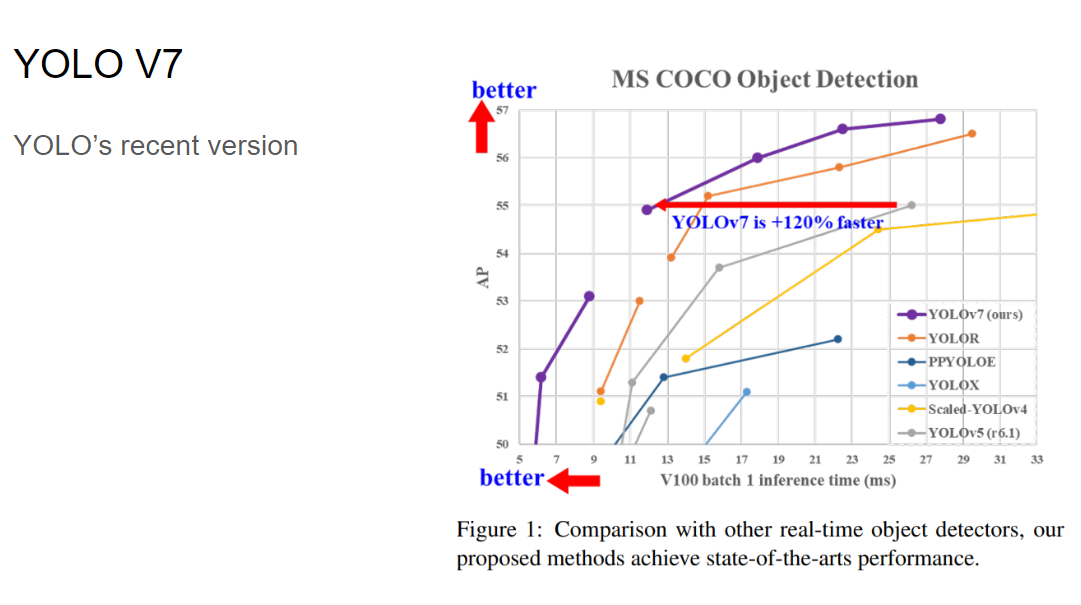

Yolo의 main contribution으로는 Object detection을 regression problem으로 관점 전환이 이루어졌다는 점과, One-Stage 방식, 즉 하나의 신경망으로 Object detection task를 수행한다는 점, 그리고 이전 모델들인 DPM,RCNN 모델보다 속도 개선이 이루어졌다는 점 등이 있습니다.
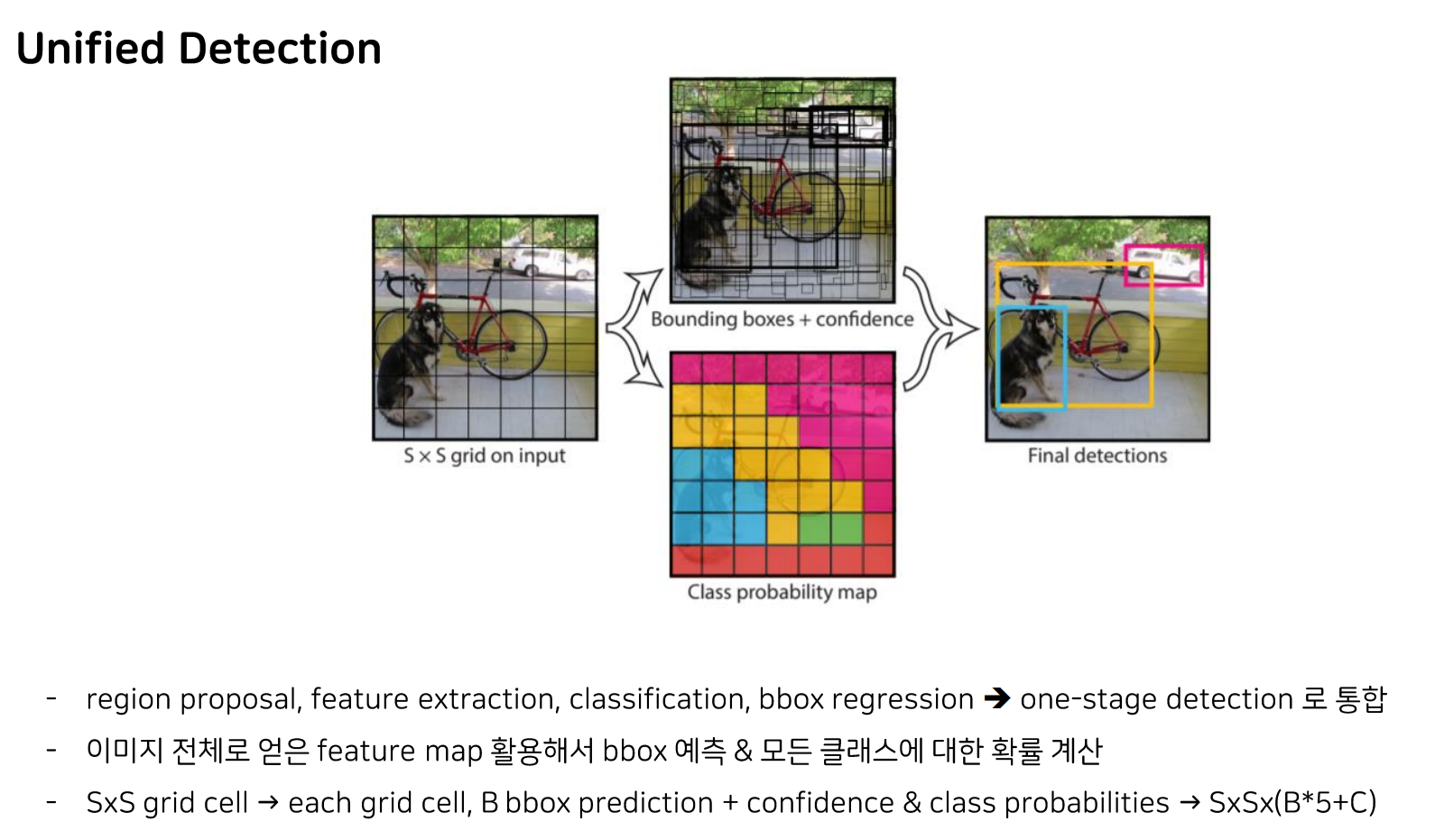
앞서 말씀드렸다시피, yolo는 one-stage detection이며, 이미지를 입력으로 어떤 CNN을 통과시켜 뽑아낸 feature map을 활용해서 bbox를 예측하고 모드 클래스에 대한 확률을 계산합니다.
또한, 이미지를 S*S크기의 그리드 셀로 나누어 각 그리드 셀마다 bounding box 예측과 그 box안에 물체가 들어있을 확률, 그리고 그리드 셀에 있는 물체의 class 예측 확률을 구하게 됩니다.
따라서 최종 output의 shape은 SXSX(B*5+C)이 되는 것입니다.

예시를 통해 자세히 설명드리겠습니다.
S가 4이고, B가 2, C가 20이라고 할 때, S는 grid size, B는 각 그리드 셀에서 예측할 Bouning box의 개수, C는 class 개수입니다. Resize된 이미지를 S가 4이므로, 4X4 grid로 분할한 다음, 각 그리드 셀마다 bbox를 2개씩 예측합니다.
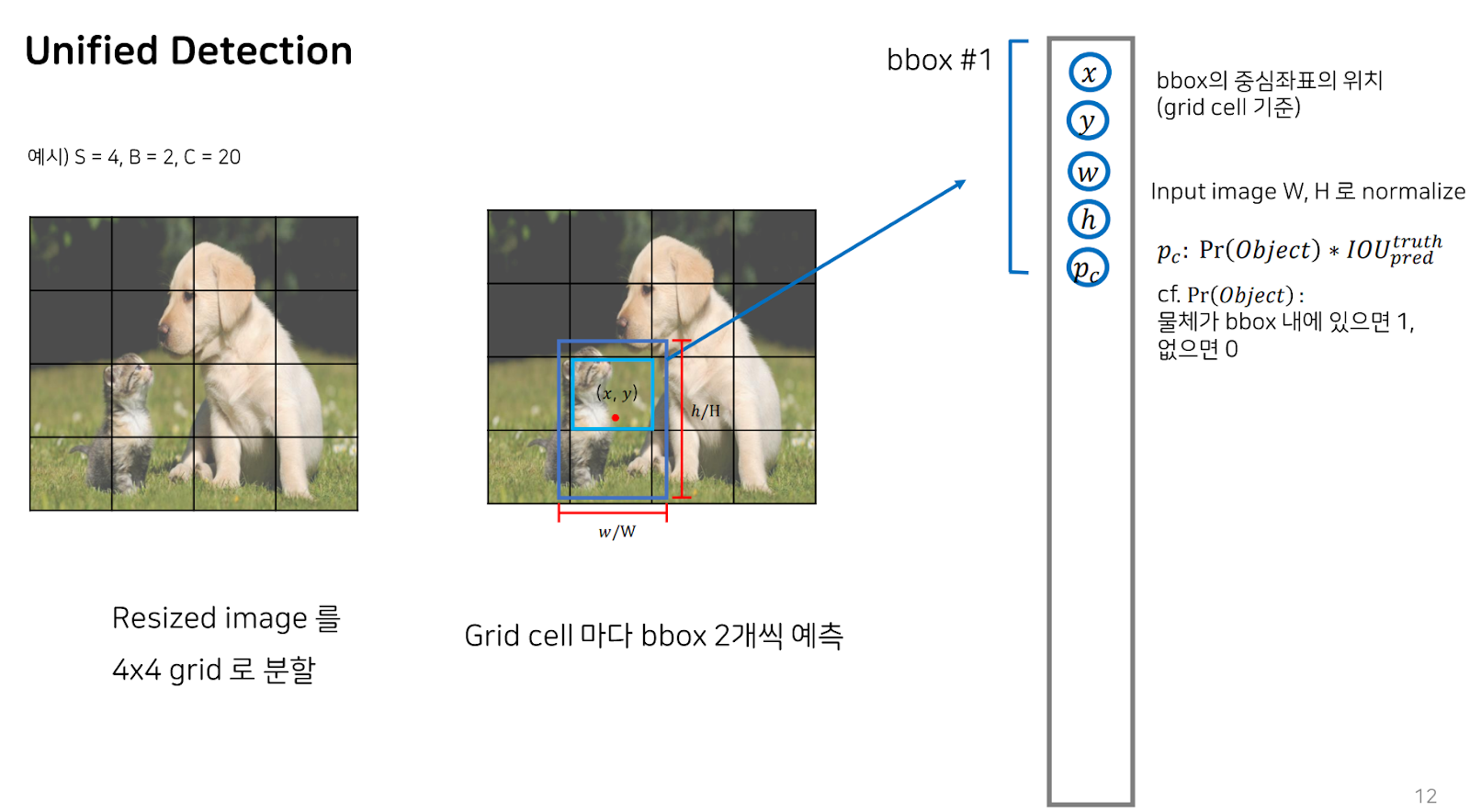
Bbox 두 개 중 하나를 예측했을 때입니다. Bbox 1은 bbox의 중심 좌표와 center point로부터의 width, height로 이루어져 있으므로, 중심좌표의 x,y 좌표와 input image의 w,h로 normalize된 w,h가 예측 아웃풋에 들어있습니다. 또한, 해당 bbox에 물체가 있는지 없는지를 판단하고 GT와의 교집 정도를 나타내는 IoU를 곱해 도출된 Pc까지 예측 아웃풋이라고 할 수 있습니다.
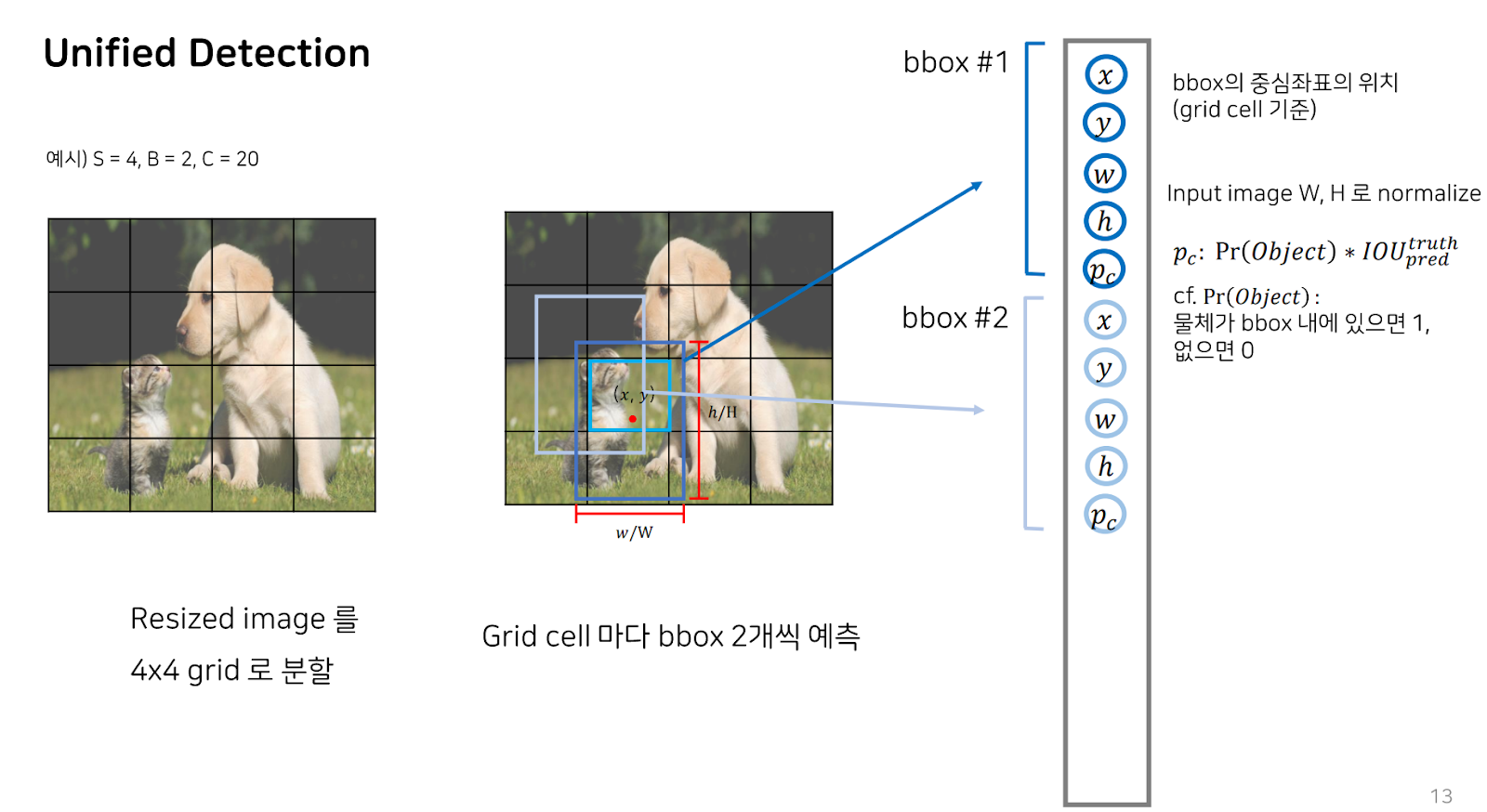
두 번째 bbox 또한 예측 아웃풋의 형태는 bbox1과 동일합니다.

각 그리드 셀마다 내놓는 아웃풋에는 앞서 언급한 bbox 2개의 정보와 물체가 bbox내에 있을 때, 해당 그리드 셀에 있는 물체가 I 번째 클래스에 속할 확률을 나타낸 총 클래스의 개수만큼의 확률들이 포함되게 됩니다.
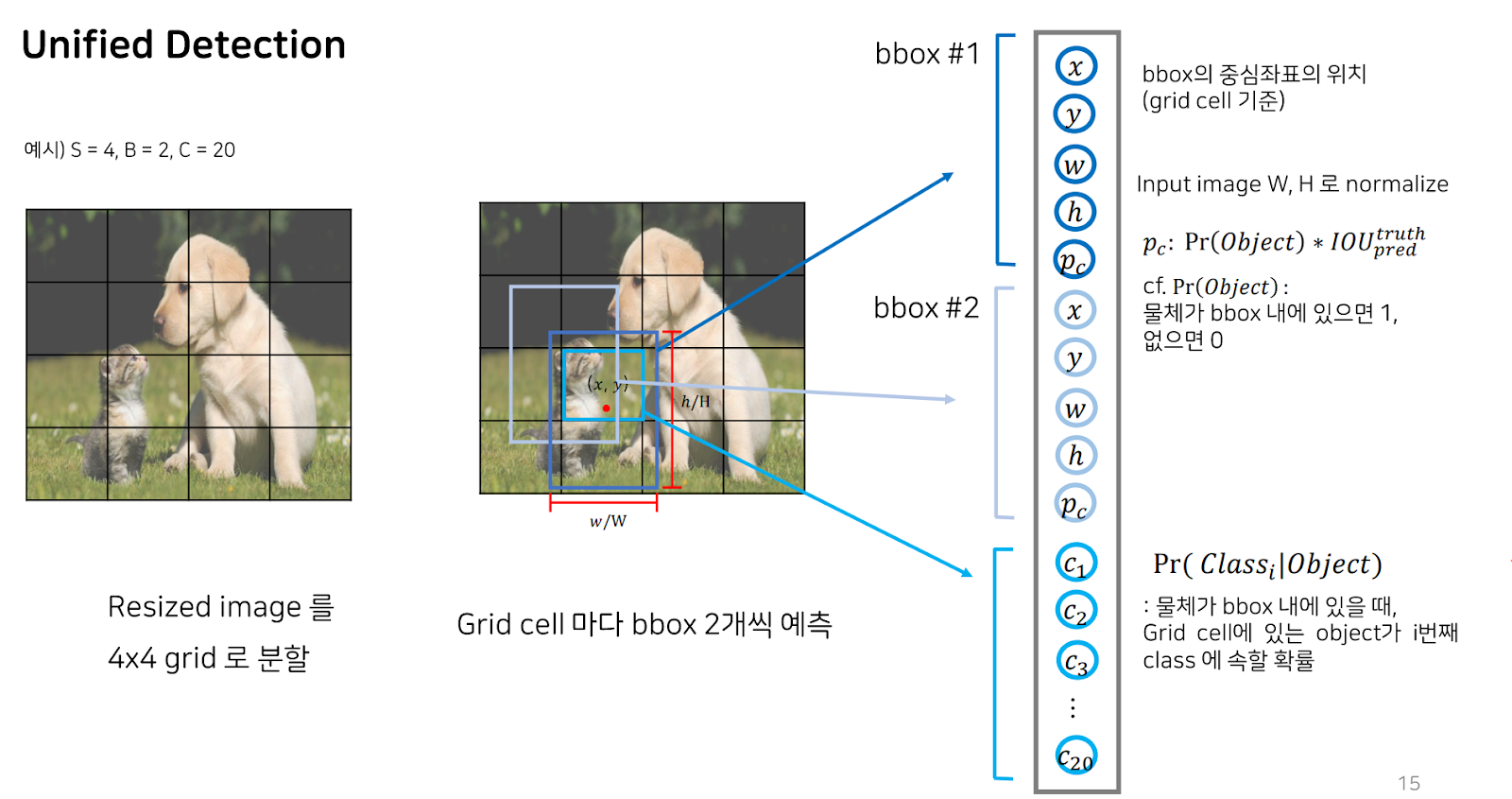
이렇게 한 그리드 셀에서 뽑아낼 수 있는 예측은 보시는 것과 같은 구성입니다.

따라서 각 그리드 셀마다 bbox 두 개에 각 bbox마다 5개의 정보를 가지고 있고, 마지막에 물체가 속한 클래스의 확률을 나타내므로 클래스 개수인 20이 더해져 각 그리드 셀마다의 output tensor의 shape은 30이 되게 됩니다. 이 전체 output tensor의 shape은 그리드셀의 개수까지 곱해 4X4X30이 됩니다.
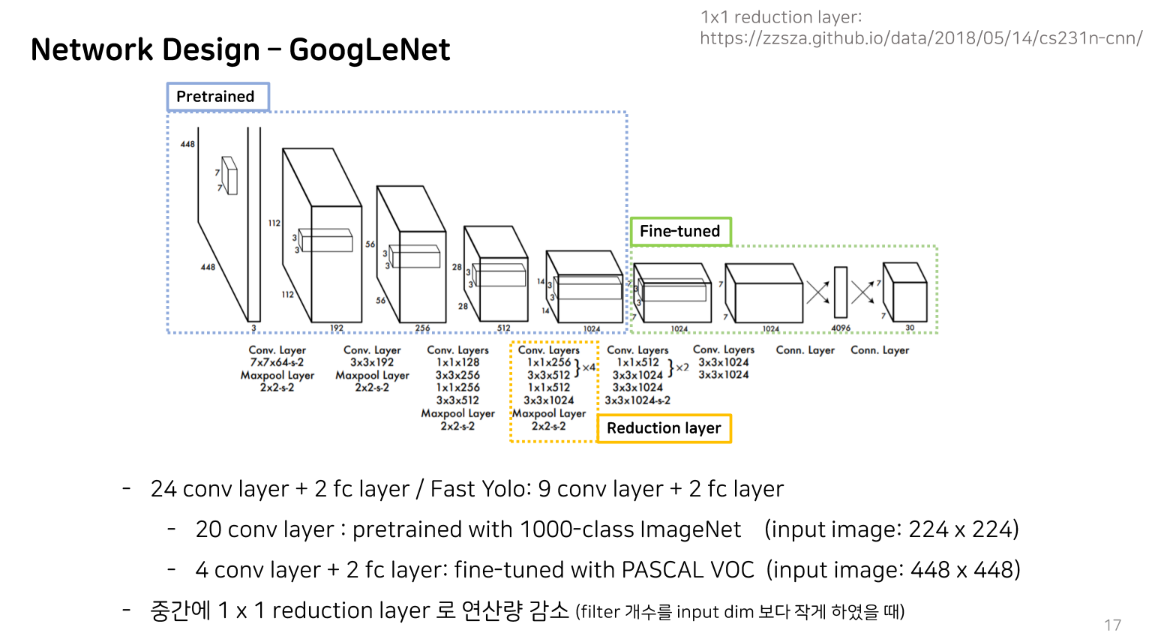
다음은 yolo의 네트워크 디자인에 대해 설명드리겠습니다. GoogleNet을 backbone으로 하였습니다. 앞의 총 20개의 conv layer는 10 class 이미지넷을 이용하여 pretraine을 하였고, 이후에 4개의 conv layer와 2개의 fc layer를 추가로 붙여서 PASCAL VOC 데이터에 대해 fone-tuning하는 과정을 거쳤습니다.
또 주의 깊게 보셔야 할 부분이 아무래도 conv layer를 많이 쌓을수록 연산량이 증가하다보니, 중간에 1X1 reduction layer로 연산량을 감소시키는 솔류션을 적용하였다고 합니다.
이에 대한 자세한 설명은 없었지만, 연산량을 줄이기 위해 흔히들 convolution 연산시 중간에 1X1 conv 연산을 진행하는 것과 비슷한 맥락이라고 파악했습니다.
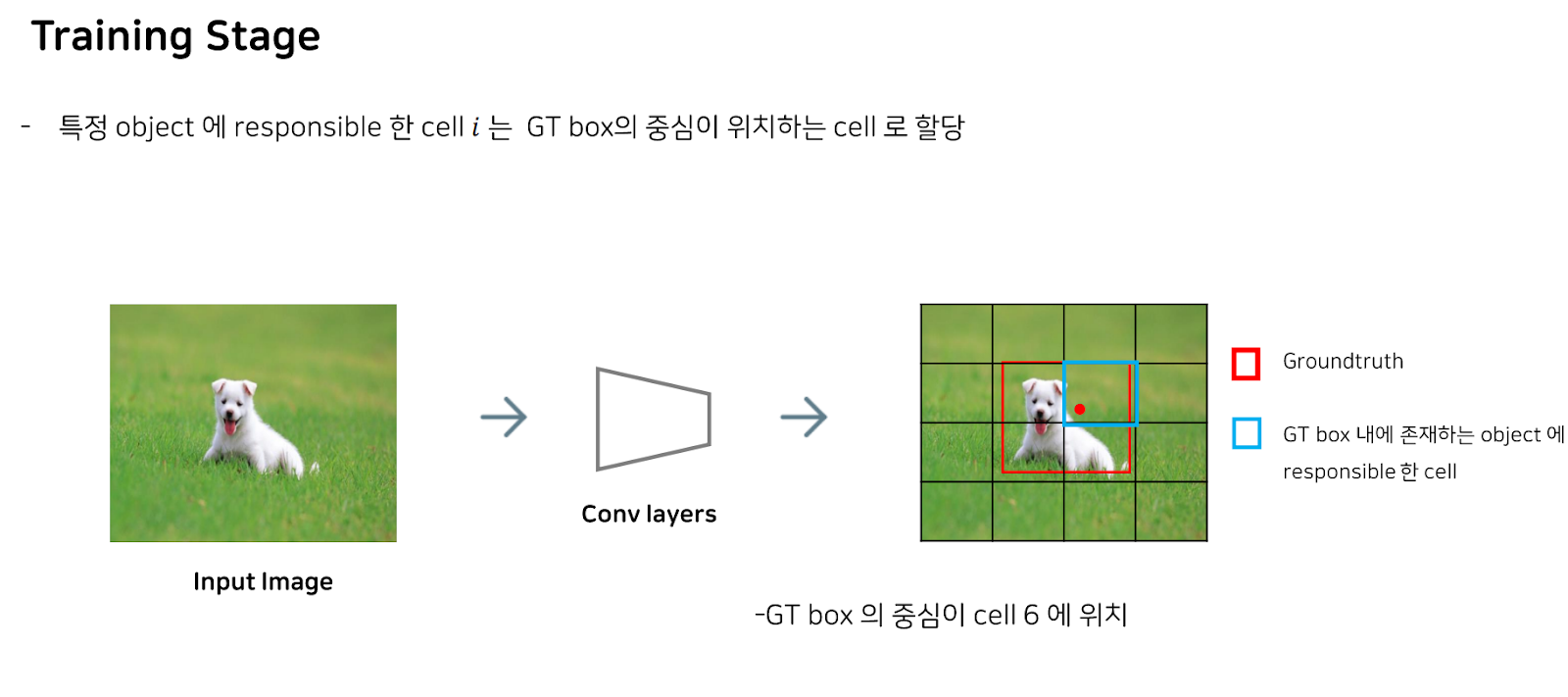
이제 output을 내는 과정을 학습하는 Training Stage에 대한 설명을 드리겠습니다.
Yolo을 학습할 때에는, 먼저 주어진 GT 박스의 중심점이 위치하는 cell을 지정합니다. 이때 이 셀을 responsible하다고 합니다.
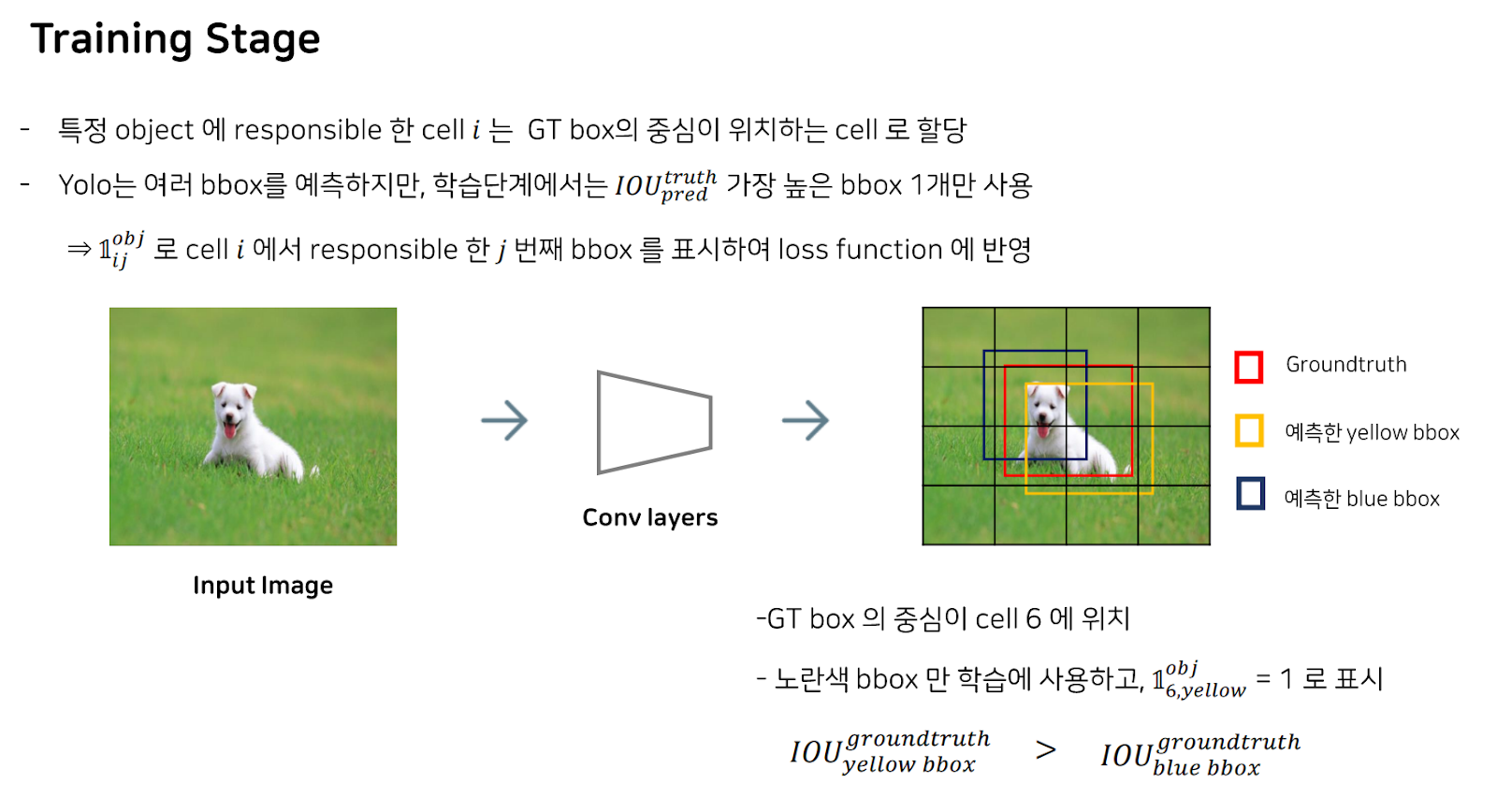
그 다음, 해당 셀에서 여러 b박스를 예측할 텐데, 학습 단계에서는 IoU 즉, intersection of Area가 가장 높은 bbox를 한 개만 사용합니다.
이 bbox를 responsible한 cell i에서 responsible한 j번째 bbox라고 하면, 이를 1로 표시함으로써 loss function에 반영합니다.

여기서의 loss function은 MSE로, 각 그리드 셀마다 도출된 하나의 bbox 정보와 GT box 정보를 비교하고, 각 그리드 셀의 class와 label class를 비교합니다.
요약하자면, 각 그리드 셀에 물체가 존재하는 경우의 오차와 최종으로 도출된 하나의 bbox, 즉 predictor box와의 오차만 학습합니다.
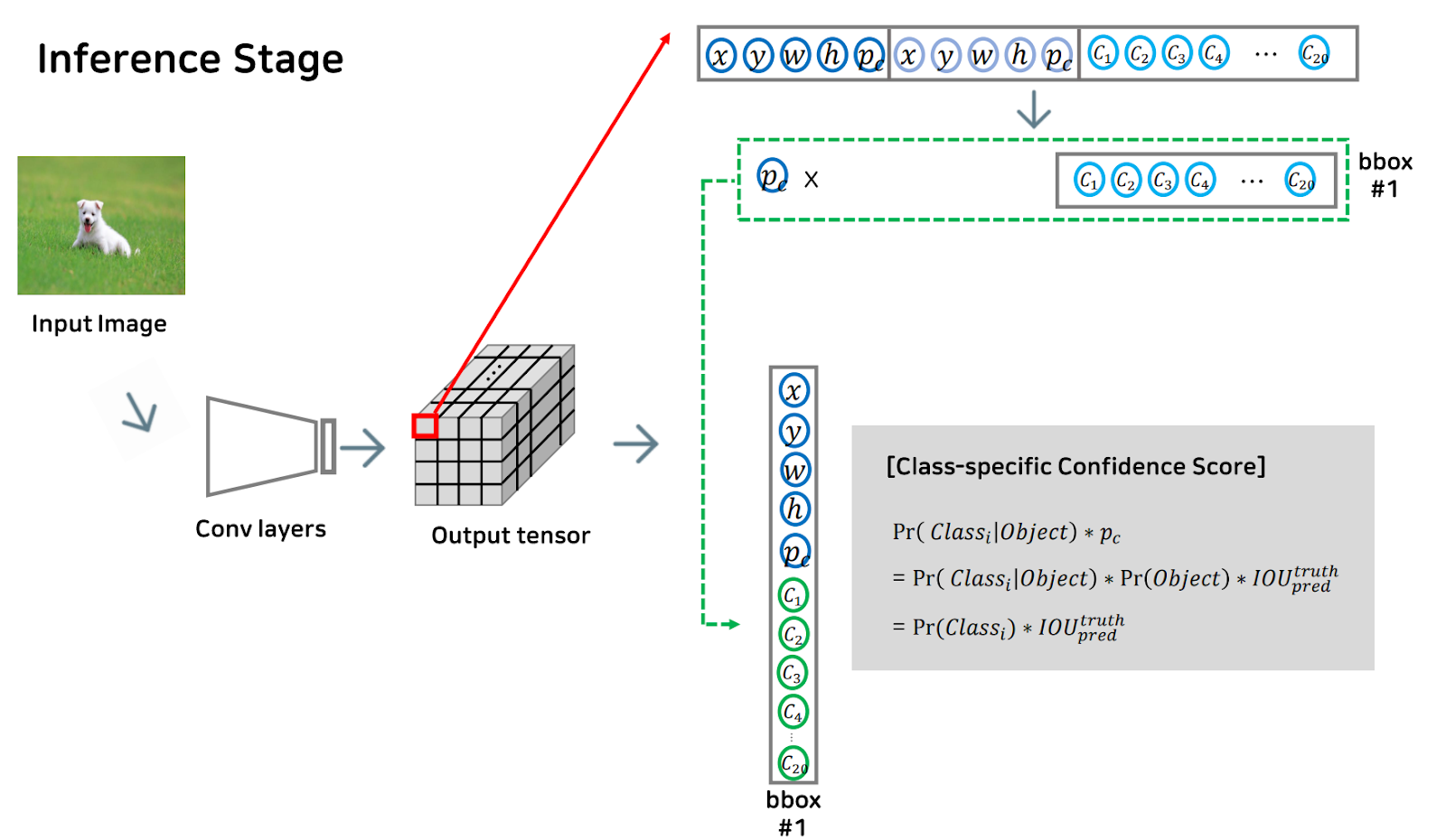
다음은 inference 단계를 구체적으로 말씀드리겠습니다.
먼저, input image가 들어왔을 때, 네트워크를 거쳐 output tensor를 도출하게 됩니다.
이 output tensor의 경우 각 그리드 셀마다 도출한 b개의 bbox 정보와 클래스 예측 확률 값이 들어있습니다.
이때, Pr, 즉 물체가 bbox안에 있을 때, 그리드 셀에 있는 물체가 i번째 class에 속할 확률을 나타냈던 하늘색의 c1,c2..등등이 물체가 bbox안에 있을 확률을 나타낸 Pc와 곱해지게 되면, 보시는 식에 따라
그리드 셀에 있는 물체가 i번째 class에 속할 확률 초록색의 c1,c2..로 바뀌게 됩니다.
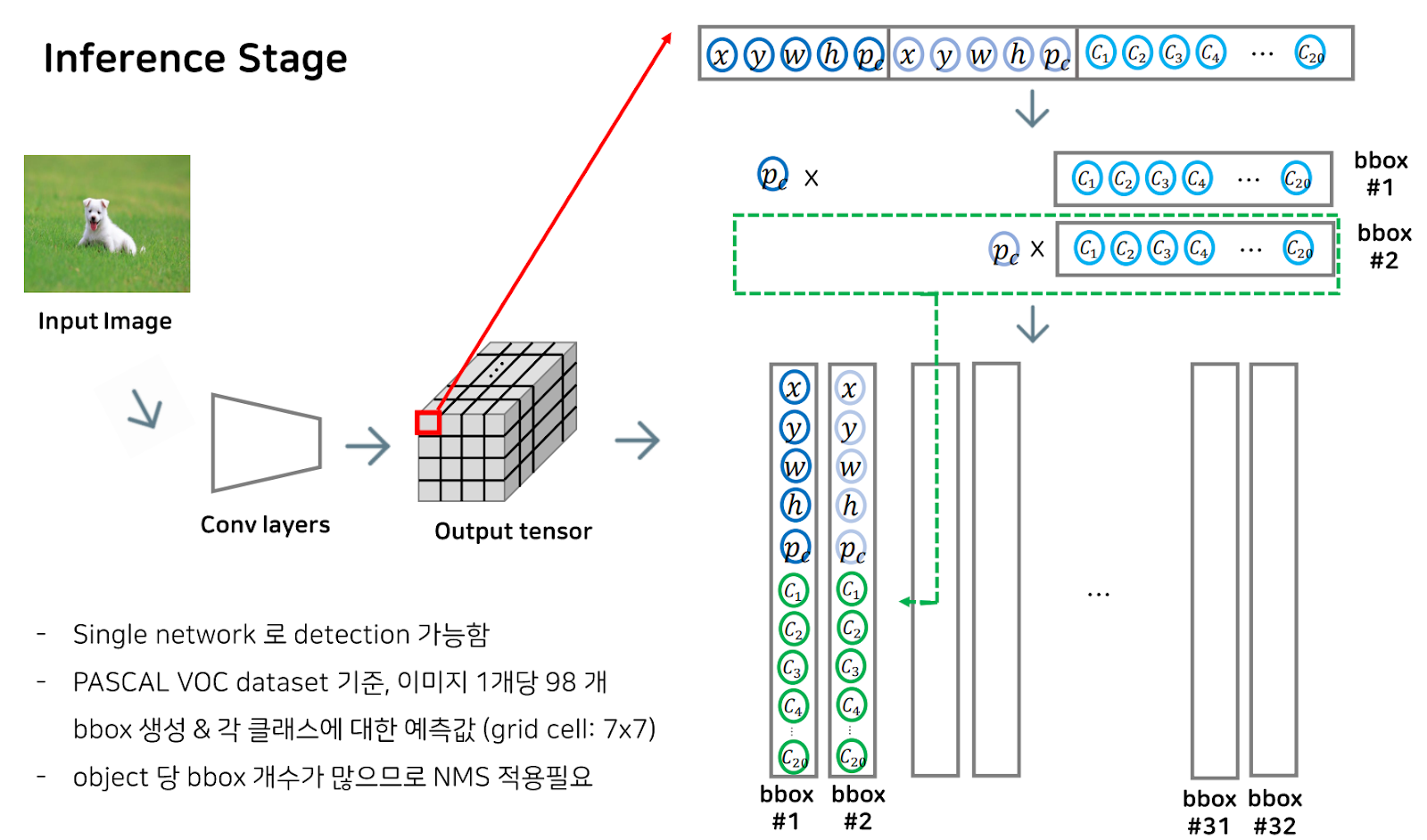
이렇게 클래스별 확률을 각 그리드 셀마다의 b개의 bbox별로 구해주게 되는데, 이렇게 되면 object당 bbox 개수가 아주 많아지므로 NMS라는 알고리즘을 적용해 bbox 개수를 object 당 하나로 정의합니다.

NMS 알고리즘이란, 각 object에 대해 예측한 여러 bbox 중에서 가장 예측력 좋은 bbox만 남기기 위한 알고리즘으로, bbox들을 모아놓고, 각 클래스 중 가장 높은 확률을 가진 bbox 하나를 골라 해당 class의 object에 가장 알맞은 박스를 남기는 것입니다.

예시를 들어보자면, object가 한 개인 경우, 강아지라는 class를 가장 잘 예측하는 bbox는 12번이고, 나머지 bbox는 12번과의 IoU가 높으니 같은 object를 나타내는 bbox라고 판단하고, 제거합니다.

같은 class에 속하는 objct가 2개인 경우에는, NMS에 의해 강아지 class를 예측하는 bbox들 중에 가장 예측률이 높은 12번을 기준으로 다른 bbox를 보았을 때, 13과 IoU가 높으므로 제거합니다.

그러나, 16번 bbox와 12번은 IoU가 낮으므로 class는 같아도 다른 object를 detect했다고 판단해 제거되지 않습니다.
이렇게 multiple object detection이 되는 것입니다.
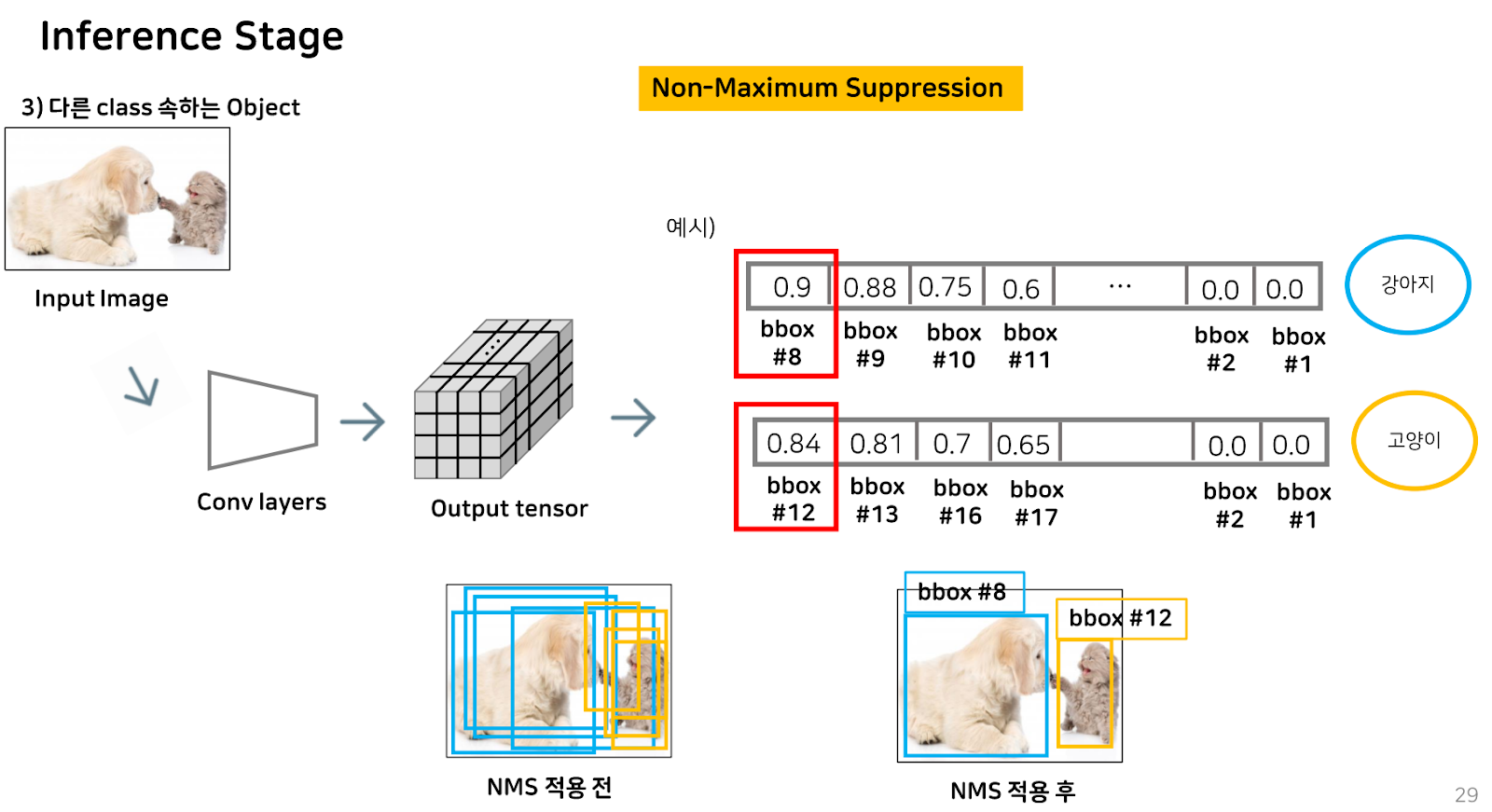
마지막으로, 다른 class에 속하는 multiple object인 경우에는, NMS에 의해 강아지 class에서 가장 강아지를 잘 예측하는 8번 bbox를 기준으로 IoU가 높은 다른 bbox를 모두 제거하고, 마찬가지로 고양이 class에서 가장 고양이를 잘 예측하는 12번 bbox를 기준으로 IoU가 높은 다른 bbox를 모두 제거하면 다른 클래스의 multiple object detection을 수행하게 되는 것을 볼 수 있습니다.

이때까지 설명드린 yolo는 버전 5의 경우이며, 전체적인 알고리즘은 모든 버전이 일맥상통하다고 볼 수 있습니다. Yolo v5의 경우, 이전까지 나온 모델에 비해 속도 면에서 확실히 빠른 것을 보였으며, 성능 또한 나쁘지 않았으나, 작은 물체나 특정 카테고리에서 정확도가 낮은 모습을 볼 수 있었습니다.

Dataset을 바꾸어 실험해보았을 때에도, 안정적인 성능을 보여, 다양한 도메인에서도 안정적인 detection 성능을 보임이 증명되었습니다.

하지만, yolo는 아직 학습 단계에서 GT와 IoU를 기준으로 predictor box 하나를 선택하기에, 작은 물체인 경우 IoU가 전체적으로 높아져 잘못된 predictor를 결정해버려 작은 물체에서의 탐지 성능은 낮다는 한계가 있습니다.