https://github.com/cvlab-stonybrook/DewarpNet
GitHub - cvlab-stonybrook/DewarpNet: Code for the paper "DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regre
Code for the paper "DewarpNet: Single-Image Document Unwarping With Stacked 3D and 2D Regression Networks" (ICCV '19) - GitHub - cvlab-stonybrook/DewarpNet: Code for the paper "D...
github.com

Dewarping Task는 구겨진 종이를 일반적인 카메라로 촬영한 3채널의 이미지를 입력으로 하였을 때, 각 픽셀이 이동해야 할 위치가 담겨있는 2채널의 Flow map을 출력으로 한 어떤 딥러닝 기반 Dewarping Network를 통해 구겨진 종이를 flow map으로 펼치는 작업입니다.
모든 딥러닝 기반 Dewarping Task 수행 network는 Flow map을 예측하는 것이 주 기능입니다.

DewarpNet은 distorted 종이 이미지가 입력으로 들어오면 flow map을 예측하여 최종적으로 펼쳐진 종이가 출력됩니다.

또, DewarpNet은 doc3D라고 불리는 아주 방대한 양의 train data set으로 학습을 시킵니다.
이 양은 대략 distoreted image만 100만장입니다.

DewarpNet은 크게 두 가지 sub 네트워크로 이루어져 있는데, 하나는 world coordinate map 예측하는 Shape Network이고, 나머지 하나는 Flow map을 예측하는 Texture mapping network 입니다.

먼저, world coordinate map 예측하는 Shape Network에 대해 설명드리겠습니다.
이 network는 doc3D data set에서 train distorted image와 상응하는 3d coordinate map을 label로 하여 loss를 줄여나가면서 학습시킵니다.
여기서 Loss는 label 3d coordinate map, 즉 C와 network의 output인 C햇 간의 L1 loss와 C와 C햇 간의 gradient loss를 구해 더함으로써 최종 loss가 됩니다.

Gradient loss는 말 그대로 C와 C햇 간의 gradient 차이입니다. 논문에서는 Image gradient loss를 구함으로써 Label C에 있는 high frequency detail들을 더 잘 학습할 수 있을 것으로 기대하였습니다. 실제로 gradient loss를 더함으로써 network 성능이 올라간 것을 논문 실험 결과에서 찾아볼 수 있었습니다.

Gradient loss 구현은 sobel을 이용해 구현하였습니다. 보시는 것과 같이 x방향, y방향으로 sobel matrix를 만들고, 이를 kernel로 사용해 C와 C햇에 channel 별로 convolution을 수행하는 모습을 볼 수 있었습니다.
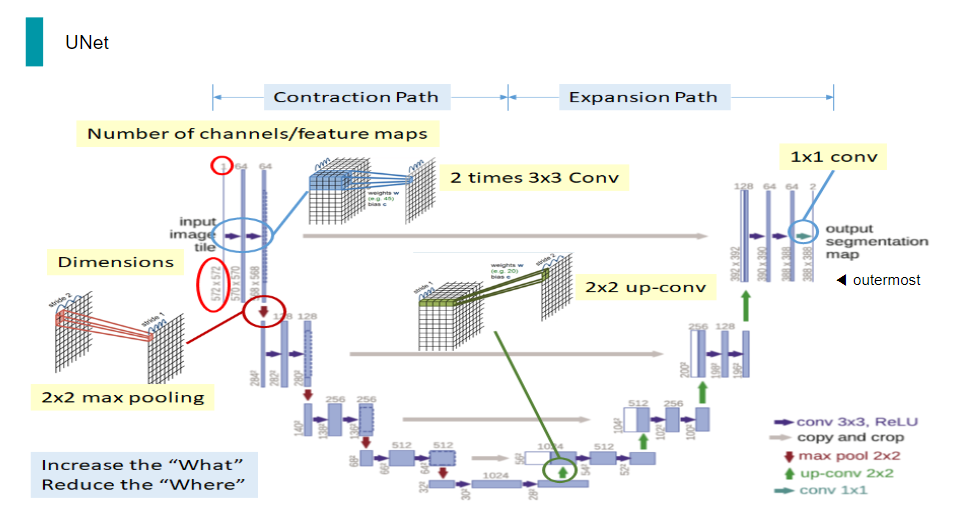
이 Shape Network의 network 구조는 전형적인 UNet 구조를 띄고 있었습니다.
Unet은 보시는 것과 같이, convolution과 deconvolution을 반복하고 중간 중간에 skip connetion을 함으로써 Low level Feature를 잡는데 매우 유용한 구조입니다.

본 논문의 Shape Network에서 실제로 코드 상의 네트워크 통과가 어떻게 이루어지는 지에 관해 직관적으로 나타낸 시각 자료를 통하여 자세히 설명 드리도록 하겠습니다.
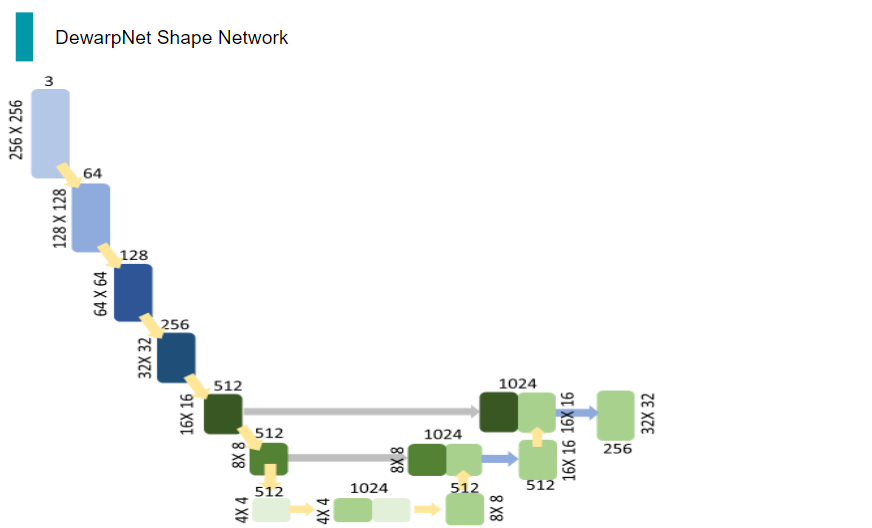
제일 먼저, network의 input으로 3채널의 이미지가 들어오면 이를 down sampling하여 채널은 높이고, 해상도는 줄입니다. 이때, down sampling은 input과 output channel수가 다르고, stride를 2로 준 Convolution연산과 ReakyReLu 연산, BatchNormalization 연산으로 이루어져 있습니다.

이 과정을 해상도가 4X4가 될 때까지 반복해줍니다.

그런 다음, 512채널의 4X4 tensor를 upsampling 해주는데, 이때 upsampling은 채널 수를 낮추거나 그대로 놔두고, 해상도를 올리는 것입니다. input과 output channel수가 다르거나 같고, stride를 2로 준 DeConvolution연산과 ReLu 연산, BatchNormalization 연산으로 이루어져 있습니다.

이렇게 해상도를 높인 512채널의 8x8 tensor는 down sampling 과정에서의 같은 채널, 해상도를 가진 tensor와 concatenation을 거쳐 채널을 두 배로 만듭니다.
이 과정을 skip connection이라고 하며, down samplig을 하면서 손실될 정보들을 고려해, 이전 정보를 후에 더해줌으로써 정보의 손실을 줄이는 대표적인 방법 중 하나입니다.

이렇게 1024채널의 8x8 tensor는 upsampling을 거치며 채널 수는 낮아지고, 해상도는 높아집니다.
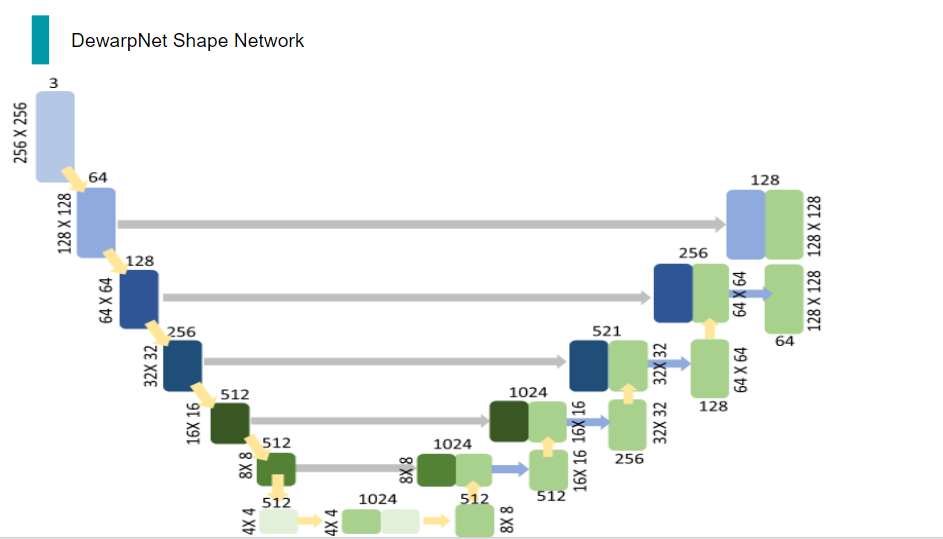
이와 같은 과정을 계속 반복하게 되면 마지막에는 원래 input과 같은 해상도와 채널 수를 가진 tensor가 출력되고, 이 tensor에는 여러 번의 downsampling 및 upsampling을 거쳤으므로 low level feature들이 잡혀 있을 것입니다.
이렇게 나온 network의 출력을 가지고 label과 loss를 구해 최적화를 시키는 방식으로 학습시킨다면, 배경과 종이 구분에 목적이 있는 네트워크, 3d coordinate map을 예측할 수 있는 네트워크인 shape network가 완성됩니다.
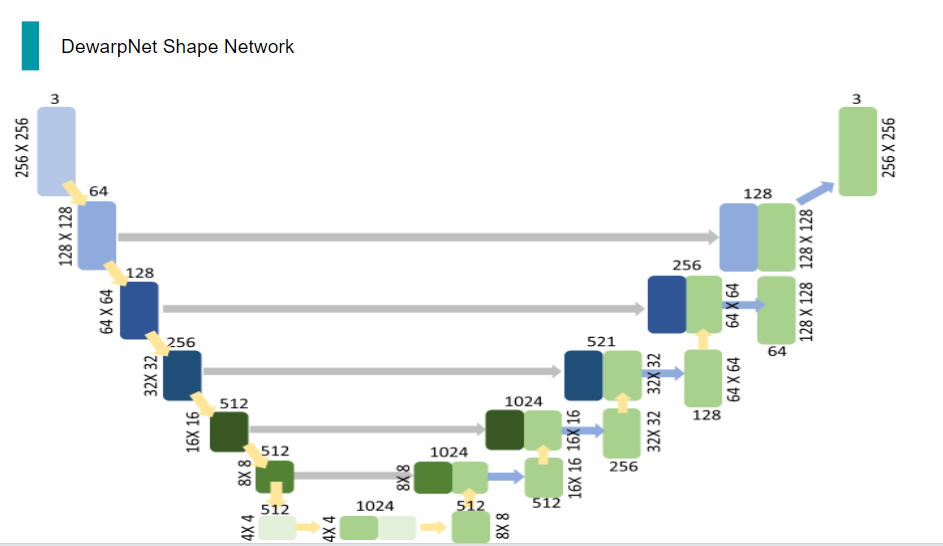
배경과 종이 구분에 목적이 있는 network
Low level Feature를 잡는데 매우 유용한 구조!
skip connection을 통해 down sampling하는 과정에서 소실되는 정보 보충
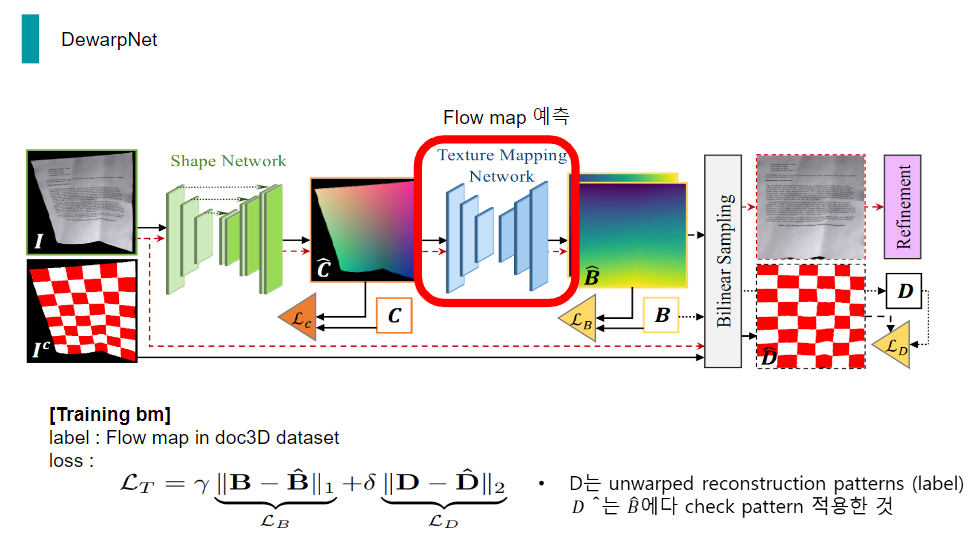
두번째 subNetwork인 Texture mapping network가 Shape network가 예측한 3d coordinate map을 입력으로 flow map을 예측하는 네트워크입니다.
이 네트워크를 학습 시킬 때에는 doc3D data set에 있는 label flow map, B와 네트워크가 예측한 flow map, B햇 간의 l1 loss가 쓰입니다.
또한, 종이 이미지의 텍스쳐에 관계없이 올바르게 펴져야 하므로, 예측한 flow map으로 retification 과정을 거친 checkboard pattern, D햇과 label flow map으로 retification 과정을 거친 checkboard pattern, D 간의 l1 loss도 쓰입니다.


이제 이 Texture mapping network의 model 구조에 관련해서 구체적으로 설명드리겠습니다.
이 또한 실제로 코드 상의 네트워크 통과가 어떻게 이루어지는 지에 관해 직관적으로 나타낸 시각 자료를 통하여 자세히 설명 드리도록 하겠습니다.
일단, 이 네트워크의 전체적인 구조는 보시는 것과 같습니다. 후에 자세한 과정을 더 설명드릴 예정입니다.
먼저, 배치 사이즈가 N이고 배경이 제거된 3채널의 3d world coordinate map이 입력으로 들어오게 되면, x,y 방향으로 총2채널의 coordinate 정보를 추가하여 5채널의 tensor가 Encoder로 들어가게 됩니다.
Encoder에서는 일련의 과정을 거쳐 128채널의 Tensor를 출력하고, 해당 Tensor는 unsqueeze과정을 두 번 거쳐 dimension을 확장한 다음, Decoder의 입력으로 들어갑니다.
Decoder에서도 일련의 과정을 거치게 되면 최종적으로 예측한 x,y 방향으로 총 2채널의 flow map이 출력되게 됩니다.

처음 입력 단계부터 다시 자세히 설명드리겠습니다.
오늘날 모든 딥러닝 분야에서 빈번히 쓰이는 Convolution은 수많은 장점이 있지만, 특히coordinate transform 문제에 굉장히 취약합니다.
여기서 coordinate transform 문제란, (x,y)라는 한 좌표가 주어졌을 때, 그 좌표에 점을 찍는 것이라고 볼 수 있습니다. 즉, 위치 정보에 관해서 convolution은 학습을 잘 하지 못하는 것이 실험과 논문을 통해 드러났습니다.
이 문제를 해결하기 위해 고안된 방법이 바로 coord conv입니다.
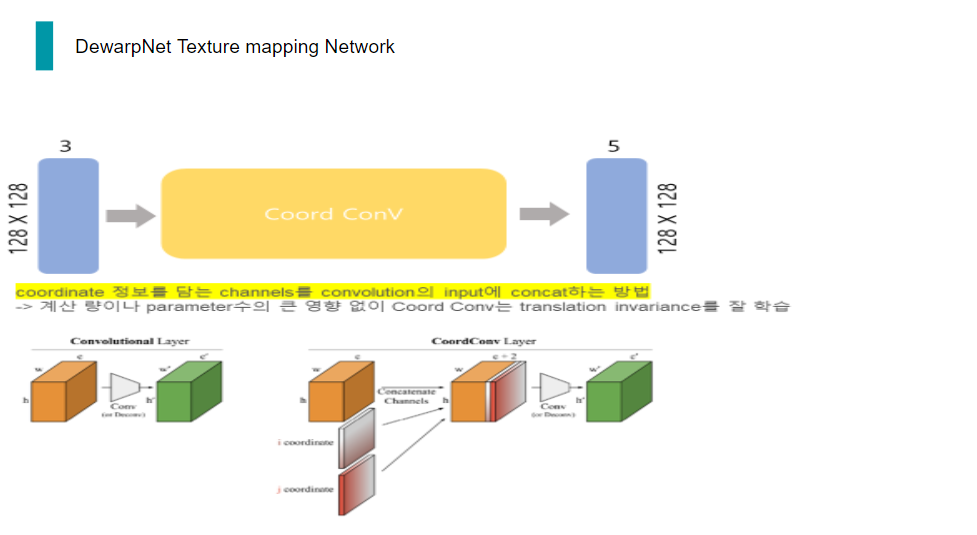
구현은 매우 간단합니다. Convolution의 input의 coordinate 정보를 추가하여 convolution을 수행하는 것입니다.
이렇게 되면, coordinate transform 문제를 해결하기 위해 학습시킬 때, 정확도도 높아지고, parameter 개수도 줄어든다는 장점이 있다고 합니다.
따라서, 3채널의 3d world coordinate map이 입력으로 들어오게 되면, 이 coord conv 과정을 거쳐 2채널의 coordinate 정보가 추가됩니다.
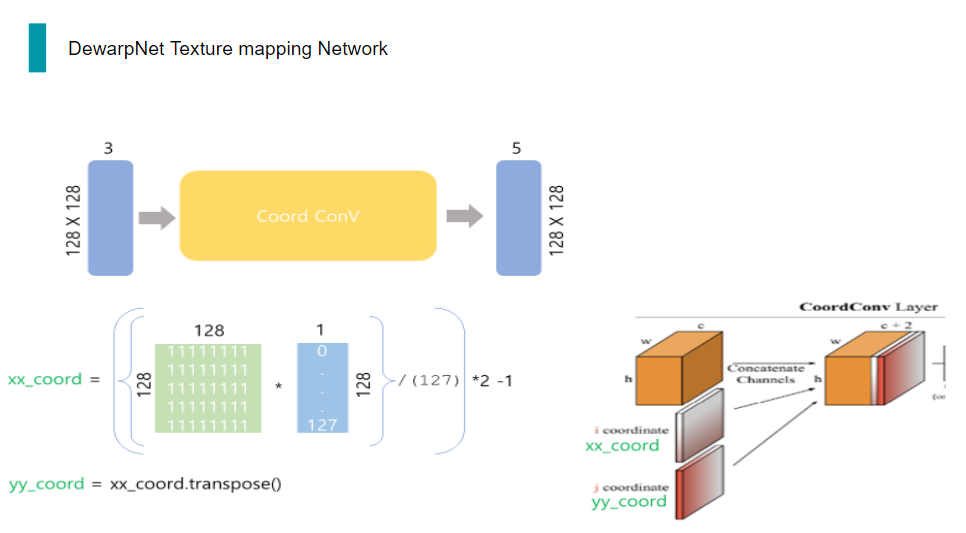
실제 코드 상에서는 보시는 것과 같이 x,y방향 coordinate를 input의 해상도를 이용해 만듭니다.
그런 다음, 이 두 coordinate 정보를 원래 이미지에 concat합니다.

이렇게 coordinate 정보를 포함한 5채널의 tensor를 convolution하여 채널은 늘리고, 해상도는 줄입니다.
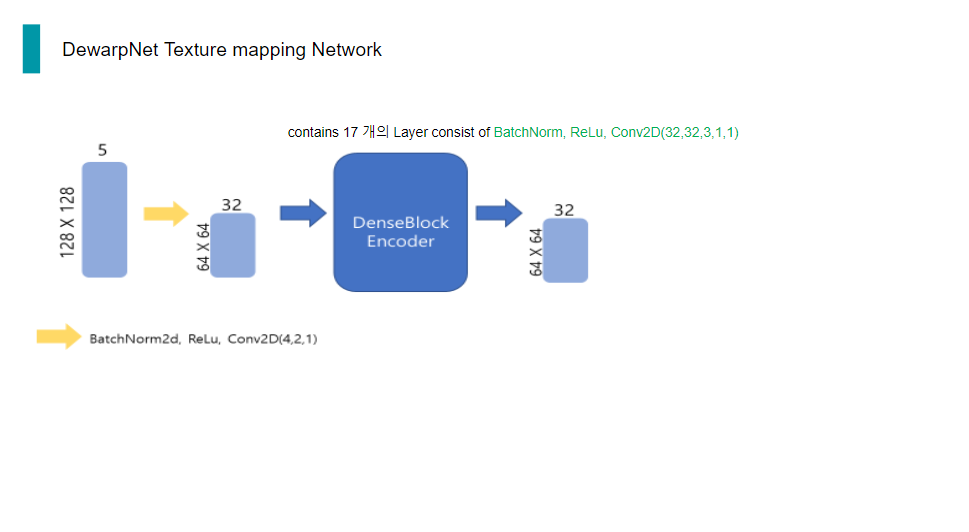
32채널의 64x64 tensor는 encoder의 입력으로 들어가게 되는데, encoder는 두 단계로 이루어져 있습니다. 첫 번째 단계인 DenseBlockEncoder는 conv 연산, BatchNorm, ReLu로 이루어진 layer 17개가 쌓인 구조입니다. 여기서 conv이 input과 output 채널이 같고, 해상도도 변함이 없으므로, 이 단계를 거치면 채널 수와 해상도에는 변함이 없습니다.
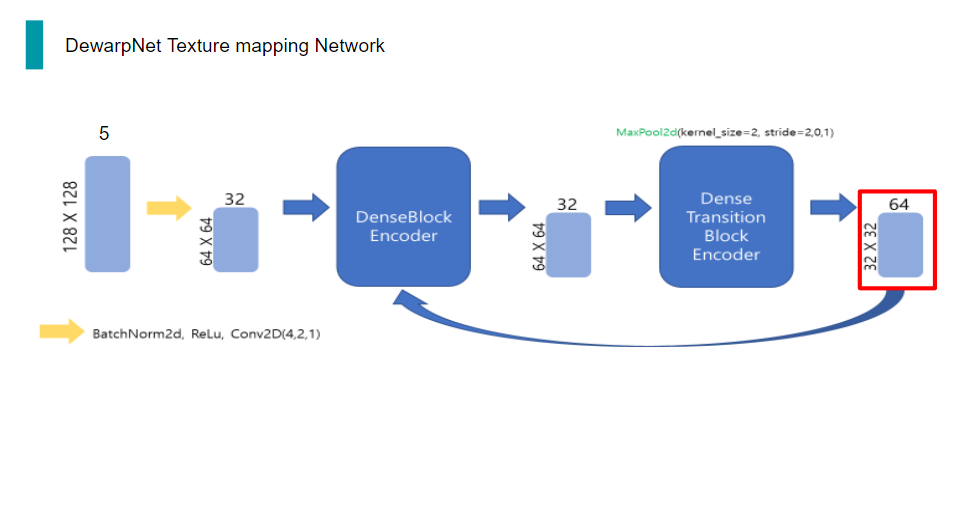
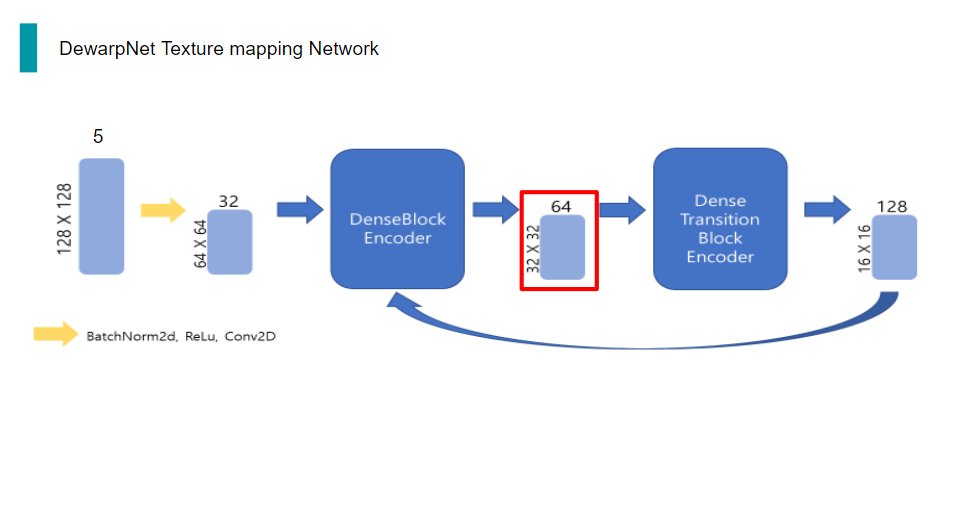
그 다음 Encoder의 두번째 단계인 DenseTransitionBlockEncoder는 BatchNorm2d,ReLu,conv,maxpooling으로 이루어진 구조입니다. 여기서 conv을 통해 채널 수를 늘려주고, maxpooling을 통해 해상도를 1/2배 줄여줍니다.

그리고 DenseTransitionBlockEncoder의 output은 다시 DenseBlockEncoder의 입력으로 들어가게 되는 구조입니다. 이 과정을 총 5번 거칩니다.

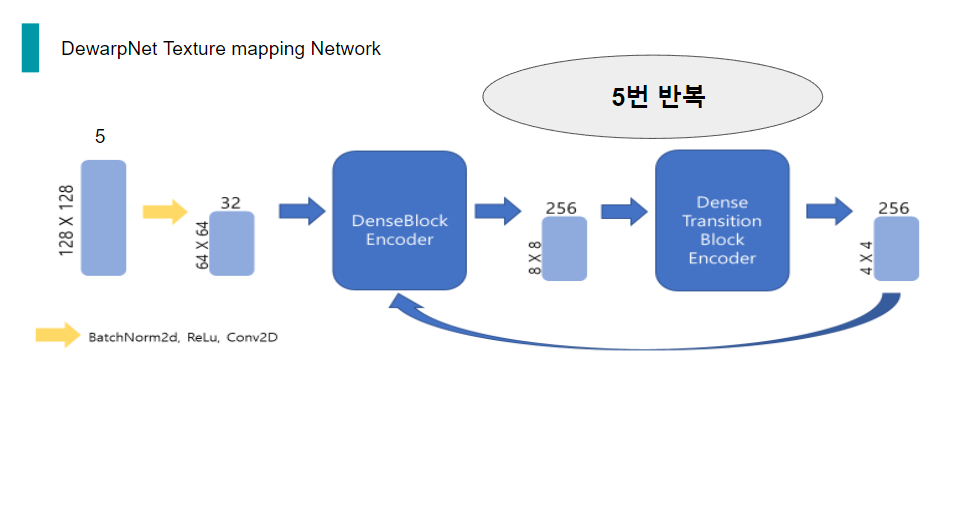
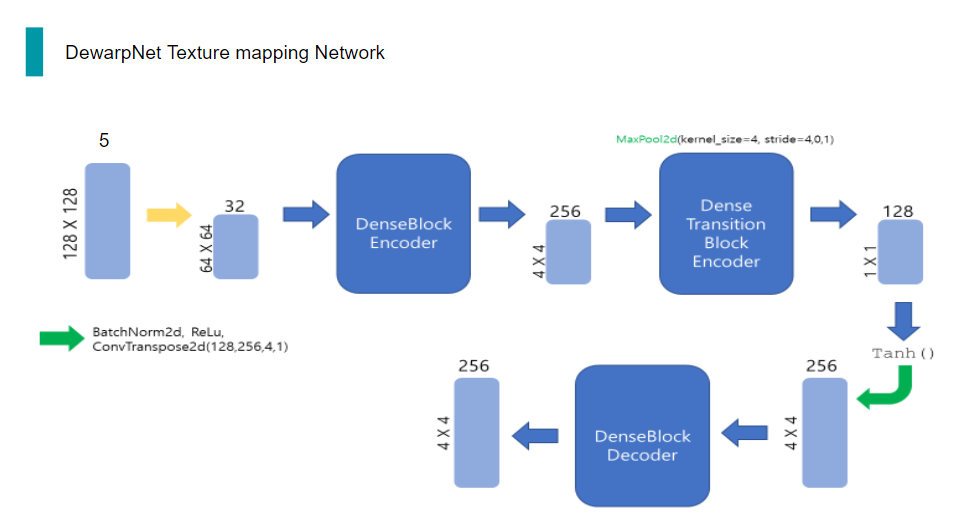
5번을 반복하고 Encoder의 최종 출력은 128채널의 1x1 tensor가 됩니다.
이를 Tanh 함수와 일련의 과정을 거친 다음, BatchNorm, ReLu, 그리고 deconvolution을 통해 채널 수와 해상도를 늘립니다.

Decoder의 구조는 Encoder에서 conv이 deconv가 된 것을 제외하고는 거의 동일합니다.
따라서 DenseBlockDecoder와 DenseTransitionBlockDecoder간 똑같이 5번의 반복을 수행합니다.
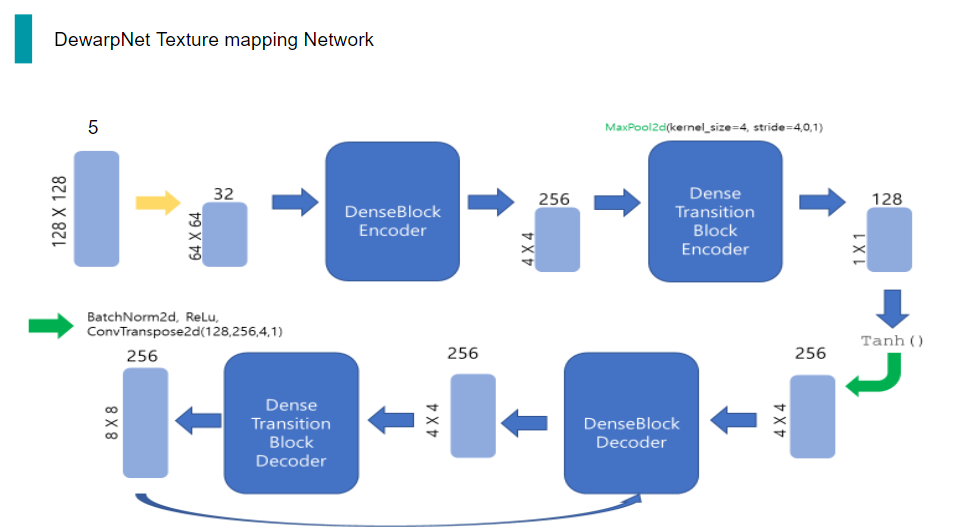

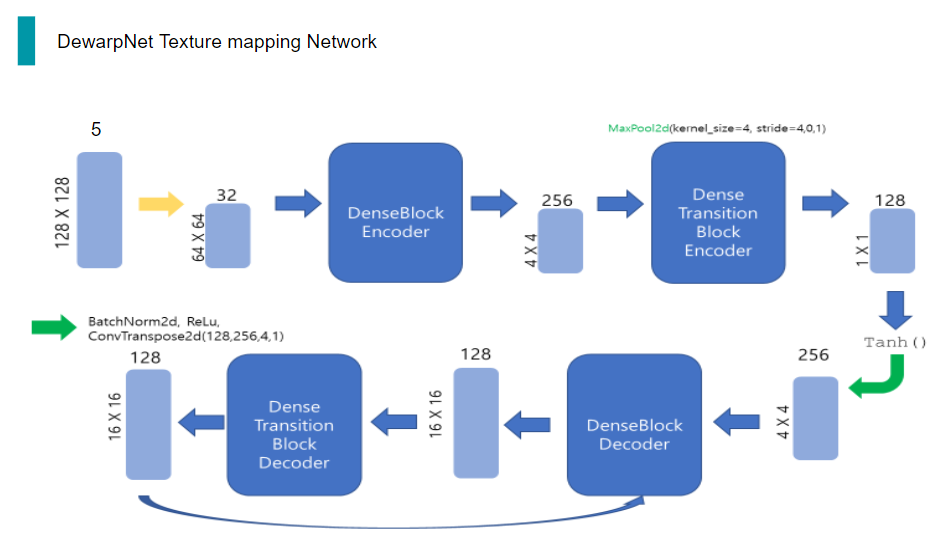
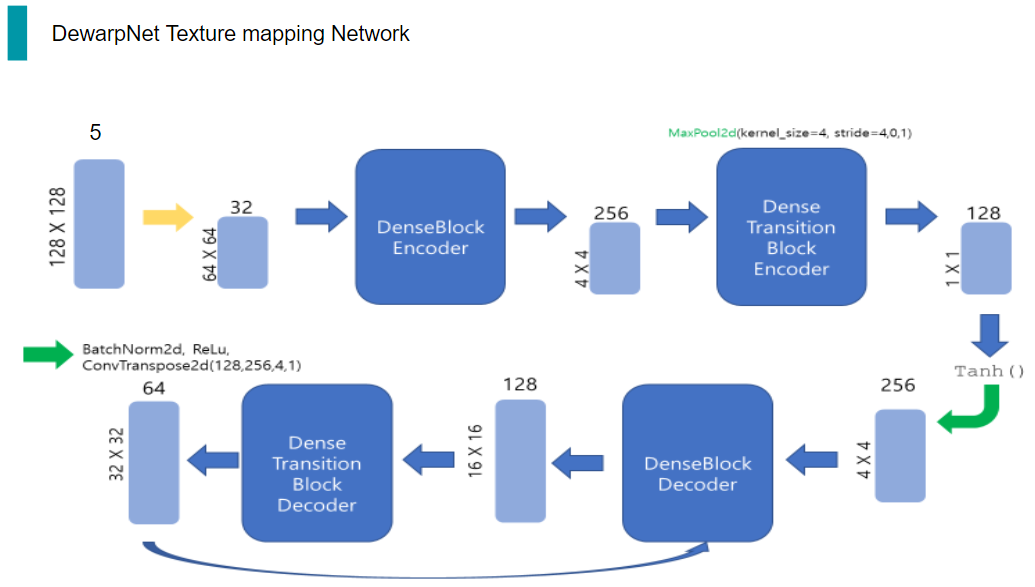

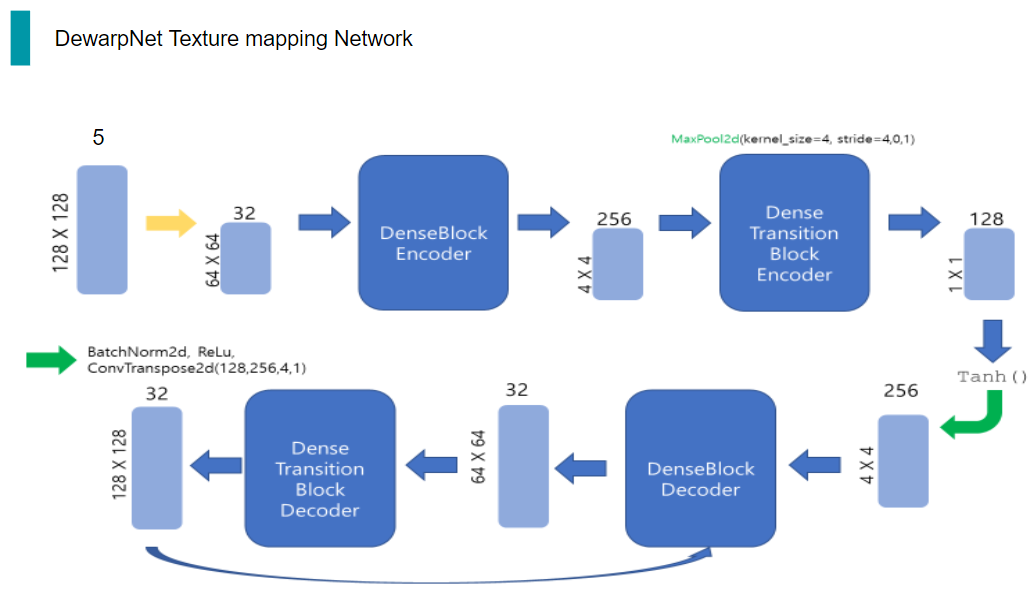
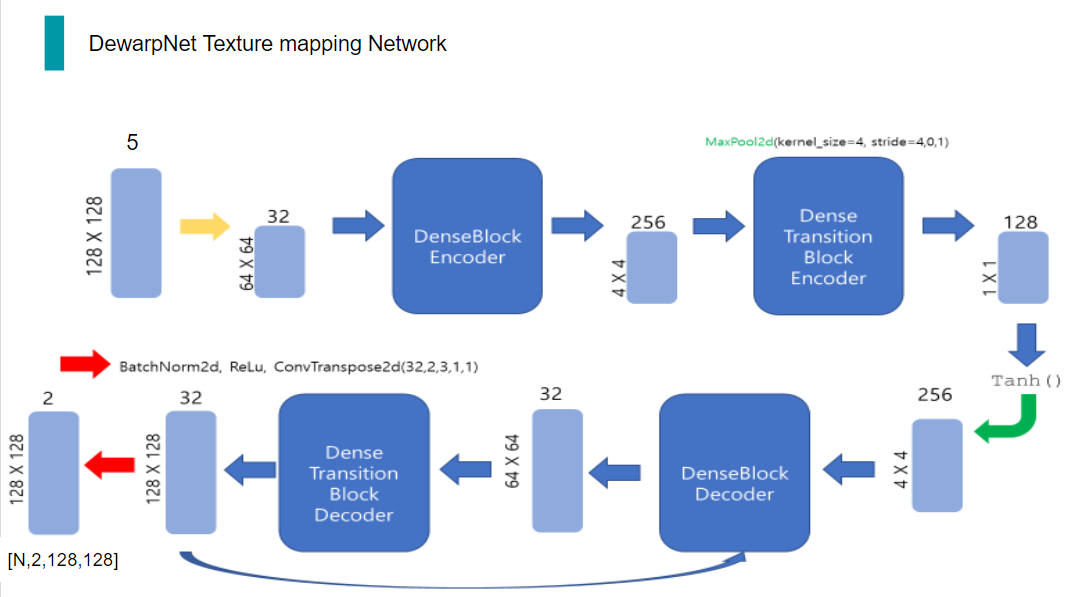
이렇게 반복을 거쳐 최종적으로 Decoder의 출력으로 나온 32채널의 128x128 Tensor는 마지막으로 BatchNorm, ReLu, 그리고 deconvolution을 통해 2채널의 tensor가 나옵니다.
이 2채널의 tensor는 이제 training 되어가는 과정에서 올바른 weight를 찾아갈 것입니다.

이렇게 나온 Texture mapping network의 output인 flow map, 즉 B햇으로 distorted image를 펼치는 과정이 실제 코드 상에서 어떻게 이루어지고 있는 지에 대해 설명 드리겠습니다.
앞에서 Distorted image의 texture에 영향을 받으면 안되므로, training시 loss를 구할 때, checkboard pattern을 펼친다고 말씀 드렸었습니다.
따라서, distorted checkboard pattern image Ic와 B햇으로 unwarping 과정이 수행됩니다.
먼저, B햇의 해상도를 Ic와 같이 만들기 위해, bileaner upsampling을 한 번 수행합니다.
그리고 난 다음, pytorch의 grid_sampling이라는 함수에 파라미터로 주기 위해, dimension을 transpose시켜주고, gird_sampling 함수로부터 B햇으로 펼쳐진 Ic, 즉 D햇을 받습니다.
여기까지 dewarpNet의 디테일한 모델 분석 및 논문 리뷰였습니다 :)
'비전딥러닝 > 논문review' 카테고리의 다른 글
| DocTr_4_GeoTr (0) | 2023.03.16 |
|---|---|
| DocTr_3_GeoTr (1) | 2023.03.16 |
| DocTr_2_UNETP (0) | 2023.03.16 |
| DocTr_1 (0) | 2023.03.15 |
| [Object Detection] Yolo + traditional Solution (0) | 2022.11.20 |