
AlexNet(one of kinds of CNN)
- AlexNet의 첫 번째 conv layers에는 많은 필터들(64개)이 있다.
Conv filters는 sliding window로 이미지를 돌고, 이미지의 일부 영역과 내적을 수행함.
이렇게 필터의 가중치와 내적한 결과가 첫 번째 Conv Layer의 출력.
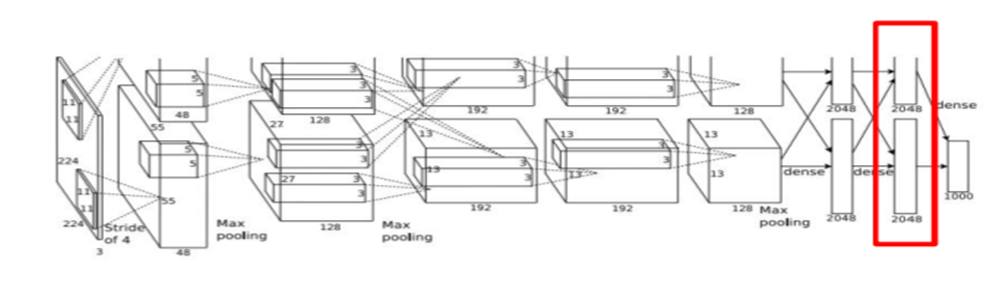
CNN의 마지막 레이어는 1000개의 클래스 스코어가 있다. 이는 학습 데이터의 predicted scores들을 의미함.
이 마지막 레이어 직전에는 Fully Connected Layer가 있음.
AlexNet의 마지막 레이어는 이미지를 포현하는 4096-dim 특징벡터를 입력으로 최종 class scores를 출력.
? 마지막 레이어에 nearest neighbor를 적용하려면 어떻게 해야하는지?
: 우선 이미지를 네트워크에 통과시킴 -> 각 이미지들에 해당하는 4096-dim 벡터들을 전부 다 저장 -> 저장된 4096-dim 벡터들을 가지고 nearest neighbor을 계산
* PCA : 4096-dim과 같은 고차원 특징벡터들을 2-dim으로 압축시키는 기법으로, 특징 공간을 조금 더 직접적으로 시각화 시킬 수 있음.
* t-SNE : 특징 공간을 시각화하기 위해서 사용하는 PCA보다 조금 더 강력한 기법.
원본 이미지를 CNN으로 4096-dim으로 줄이고 이를 다시 t-SNE로 2-dim으로 줄임.
네트워크의 입력은 3X224X224, 여러 레이어를 통과하는데, 각 레이어는 3차원(width X height X Depth)의 값을 반환.
이 3차원 덩어리(chunk, activation volume)가 바로 네트워크 레이어가 출력하는 값.
이 덩어리를 하나씩 잘라내면(slice) 그것이 바로 activation map.
● Saliency Maps
: 입력 이미지의 각 픽셀들에 대해서, 예측한 클래스 스코어의 그레디언트를 계산하는 방법.
일종의 “1차 근사적 방법”으로 어떤 픽셀이 영향력 있는 지를 알려줌.
입력 이미지에 의존적.
● guided back propagation
어떤 한 이미지가 있을 때, 이제는 클래스 스코어가 아니라 네트워크의 중간 뉴런을 하나 고른다.
그리고 입력 이미지의 어떤 부분이, 내가 선택한 중간 뉴런의 값에 영향을 주는 지를 찾는 것.
중간 레이어가 무엇을 찾고 있는지를 이해하기 위한 영상을 합성하는데 아주 유용함.
입력 이미지에 의존적.
● gradient ascent
지금까지는 loss를 최소화시켜 네트워크를 학습시키기 위해 Gradient decent를 사용.
여기에서는 네트워크의 가중치들을 전부 고정시킴 -> 가중치 최적화 X
Gradient ascent를 통해 중간 뉴런 혹은 클래스 스코어를 최대화 시키는 이미지의 픽셀 값을 바꿔주는 방법.
Regularization term(가중치들이 학습 데이터로의 과적합을 방지하기 위한 것)이 필요함.
: 여기서는 생성된 이미지가 특정 네트워크의 특성에 완전히 과접합 되는 것을 방지하기 위함.
: 생성된 이미지가 비교적 자연스럽도록 강제하는 역할
Regularization term을 추가함으로서, 우리는 생성된 이미지가 두 가지 특성을 따르길 원함.
1. 이미지가 특정 뉴런의 값을 최대화 시키는 방향으로 생성되길 원하는 것.
2. 이미지가 자연스러워 보여야함
● Feature Inversion
: 어떤 이미지가 있고, 이 이미지를 네트워크에 통과시킨 후, 네트워크를 통과시킨 특징(activation map)을 저장해둔다. 이제는 이 특징(activation map)만 가지고 이미지를 재구성해 볼 것.
해당 레이어의 특징 벡터로부터 이미지를 재구성해보면, 이미지의 어떤 정보가 특징 벡터에서 포착되는지를 짐작할 수 있을 것.
이 방법에서 또한 regularizer를 추가한 gradient ascent를 이용.
스코어를 최대화 시키는 것 대신, 특징 벡터 간의 거리를 최소화 시키는 방법을 이용.
기존에 계산해 놓은 특징 벡터와, 새롭게 생성한 이미지로 계산한 특징벡터 간의 거리를 측정하는 것.
* total variation regularizer : 상하좌우 인접 픽셀 간의 차이에 대한 패널티를 부여하여 생성된 이미지가 자연스러운 이미지가 되도록 해줌.
네트워크가 깊어질수록 픽셀 값이 정확히 얼마인지와 같은 정보들은 전부 사라지고, 대신에 색이나 텍스처와 같은 미세한 변화에 더 강인한 의미론적 정보들만을 유지하려 하는 것일지 모름…?
★ Neural Texture Synthesis (텍스처 합성)
- Gram matrix(공간 정보를 모두 날려버림, because 이미지의 각 지점에 해당하는 값들을 모두 평균화 시켰기 때문)라는 개념 이용
Input 텍스처 사진을 네트워크(CNN)에 통과시킨 후, 네트워크의 특정 레이어에서 특징 맵을 가져온다. 이 특징 맵을 가지고 입력 이미지의 텍스트 기술자(descriptor)를 계산할 것.
★ Neural Style Transfer
- Input : Content Image (네트워크에게 우리의 최종 이미지가 어떻게 생겼으면 좋겠는지를 알려줌), Style Image(최종 이미지의 텍스처가 어뗐으면 좋겠는지)
최종 이미지는 content image의 feature reconstruction loss도 최소화하고, Style image의 gram matrix loss도 최소화하는 방식으로 최적화하여 생성해 낸다.
더 자세히) 네트워크에 content/style 이미지를 통과시키고 gram matrix와 feature map을 계산-> 최종 출력 이미지는 랜덤 노이즈로 초기화->forward/backward를 반복하여 계산하고 gradient ascent를 이용해서 이미지를 업데이트함
'비전딥러닝 > cs231n' 카테고리의 다른 글
| Lecture 14. Deep Reinforcement Learning (0) | 2022.09.18 |
|---|---|
| Lecture 13 Generative Models (0) | 2022.09.18 |
| Lecture 11. Detection and segmentation (0) | 2022.09.18 |
| Lecture 10. Recurrent Neural Networks. (0) | 2022.09.18 |
| Lecture 9. CNN Architectures (0) | 2022.09.18 |